
minhui study
03. 선형 회귀, 경사하강법 본문
선형 회귀
1차 함수로 이해하는 선형 회귀
y = ax + b
위 1차 함수의 기울기는 a이고 절편은 b이다.
▶ 선형 회귀는 기울기와 절편을 찾아준다.
선형 회귀의 주요 관심사는 '절편과 기울기를 찾는 것'이다.
▶ 그래프를 통해 선형 회귀의 문제 해결 과정을 이해한다.
문제 해결을 위해 당뇨병 환자의 데이터 준비하기
▶ 사이킷런에서 당뇨병 환자 데이터 가져오기
1. load_diabetes()함수로 당뇨병 데이터 준비하기

사이킷런의 데이터 세트 중 당뇨병 환자의 데이터 세트를 가져온다.
datasets모듈에 있는 load_diabetes()함수를 임포트한 후 매개변수 값을 넣지 않은 채로 함수를 호출하면 diabetes에 당뇨병 데이터가 저장된다.
diabetes변수에 저장된 데이터의 자료형은 파이썬 딕셔너리와 유사한 Bunch 클래스이다.
2. 입력과 타깃 데이터의 크기 확인하기

data는 442 x 10 크기의 2차원 배열이고 target은 442개의 요소를 가진 1차원 배열이다.
diabetes.data의 행은 sample이고, 열은 샘플의 특성feature이다.

sample이란 당뇨병 환자에 대한 특성으로 이루어진 데이터 1세트를 의미하고, feature은 당뇨병 데이터의 여러 특징들을 의미한다. 이 때 입력 데이터의 특성은 다른 말로 속성, 독립 변수, 설명 변수 등으로 부른다.
3. 입력 데이터 자세히 보기
슬라이싱을 사용해 입력 데이터 앞부분의 샘플 3개만 출력했다.
10개의 특성을 가진 3개의 샘플을 추출했으므로 3 x 10 크기의 배열이 나타난다.

4. 타깃 데이터 자세히 보기
타깃 데이터도 3개만 출력하였고, 타깃 데이터는 10개의 요소로 구성된 샘플 1개에 대응된다.

당뇨병 환자 데이터 시각화하기
1. 맷플롯립의 scatter()함수로 산점도 그리기
당뇨병 데이터 세트에는 10개의 특성이 있는데 그 특성들을 모두 그래프로 표현하려면 3차원 이상의 고차원 그래프를 그려야하므로 1개의 특성만 사용하여 3번째 특성과 타깃 데이터로 산점도를 그리면 다음과 같다.

→ 그래프의 x축은 diabetes.data의 3번째 특성이고 y축은 diabetes.target이다. 이 그래프를 보면 3번째 특성과 타깃 데이터 사이에 정비례 관계가 있음을 알 수 있다.
2. 훈련 데이터 준비하기
데이터의 3번째 특성과 타겟을 미리 따로 분리해서 각 각 변수 x와 변수 y에 저장해서 사용할 수 있다.

경사 하강법
선형 회귀와 경사 하강법의 관계
선형 회귀는 입력 데이터와 타깃 데이터를 통해 기울기와 절편을 찾는 것이 목표이다.
경사 하강법은 모델이 데이터를 잘 표현할 수 있도록 기울기를 사용하여 모델을 조금씩 조정하는 최적화 알고리즘이다.
예측값과 변화율
딥러닝 분야에서 기울기 a를 가중치를 의미하는 w나 계수를 의미하는 θ로 표기하고, y는 y^(와이 햇 y_hat)으로 표기한다.
y_hat=wx+b에서 가중치 w와 절편 b는 알고리즘이 찾는 규칙을 의미하고, y_hat은 예측값이다.
1. 예측값
▷ 예측값이란?
입력과 출력 데이터를 통해 규칙을 발견하면 모델을 만들었다고 한다. 그 모델에 대해 새로운 입력값을 넣으면 어떤 출력이 나오는데 이 값이 모델을 통해 예측한 값이다.
▶ 예측값으로 올바른 모델 찾기
여기서 우리가 찾고 싶은 것은 훈련 데이터에 잘 맞는 w와 b이다.
< 훈련 데이터에 잘 맞는 w와 b를 찾는 방법 >
(1) 무작위로 w와 b를 저한다.
(2) x에서 샘플 하나를 선택하여 y_hat을 계산한다.
(3) y_hat와 선택한 샘플의 진짜 y를 비교한다.
(4) y_hat이 y와 더 가까워지도록 w, b를 조저한다.
(5) 모든 샘플을 처리할 때까지 다시 (2)~(4) 항목을 반복한다.
▶ 훈련 데이터에 맞는 w와 b찾아보기
1. w와 b 초기화하기
w와 b를 무작위로 초기화한다. 여기서는 일단 간단하게 두 값을 모두 실수 1.0으로 정하였다.

2. 훈련 데이터의 첫 번째 샘플 데이터로 y_hat 얻기
임시로 만든 모델로 훈련 데이터의 첫 번째 샘츨 x[0]에 대한 y_hat을 계산한 후 변수에 저장한다.

3. 타깃과 예측 데이터 비교하기
첫 번째 샘플 x[0]에 대응하는 타깃값 y[0]을 출력하여 y_hat값과 비교한다.

4. w값 조절해 예측값 바꾸기
y_hat 값 1.061...과 타깃 151.0은 차이가 매우 크므로 w와 b를 바꾸어야 한다.
w와 b를 조금씩 변경해가면서 y_hat값이 증가하는지 또는 감소하는지 살펴보자. 먼저 w를 0.1만큼 증가시키고 y_hat의 변화량을 관찰해보면 다음과 같이 y_hat보다 아주 조금 더 증가한 것을 확인할 수 있다.

5. w값 조정한 후 예측값 증가 정도 확인하기

w가 0.1만큼 증가했을 때 y_hat은 0.0616...만큼 증가하였는데 이 값을 훈련 데이터 x[0]에 대한 w의 변화율이라고 한다.
w_rate에 대한 코드를 수식으로 정리해 보면 변화율은 결국 훈련 데이터의 첫 번째 샘플인 x[0]이라는 것을 알 수 있다

정리해보면 위의 경우 변화율은 양수이므로 w값을 증가시키면 y_hat의 값을 증가시킬 수 있지만 만약 변화율이 음수라면 w값을 감소시켜야 y_hat의 값을 증가시킬 수 있다. 이 방법은 변화율이 양수와 음수일 때를 구분해야 하므로 번거롭다.
2. 변화율
위 문제를 효율적으로 해결하는 방법이 바로 변화율이다.
▶ 변화율로 가중치 업데이트하기
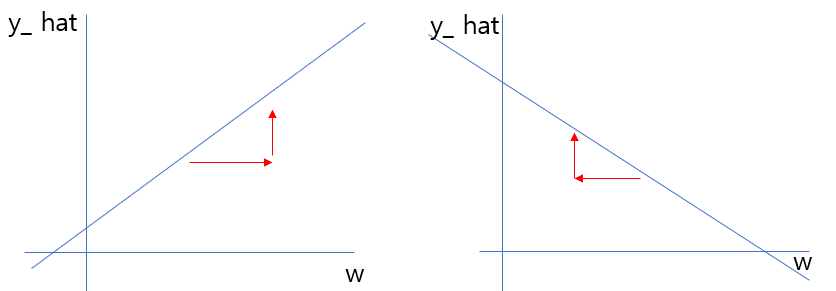
위의 상황에서 w가 증가하면 y_hat은 감소하고 반대로 w가 감소하면 y_hat은 증가한다. 이때 변화율이 음수인 점을 이용하면 변화율을 더하는 방법으로 y_hat의 값을 증가시킬 수 있다. 즉, 그냥 w에 w_rate를 더하면 되는 것이다.
결과적으로 가중치 w를 업데이트하는 방법은 w + w_rate이다.

▶ 변화율로 절편 업데이트하기
절편 b에 대한 변화율을 구한 다음 변화율로 b를 업데이트하자.
b를 0.1만큼 증가시킨 후 y_hat이 얼마나 증가했는지 계산하고 변화율도 계산한다.

변화율이 1이 나왔다. 즉, b를 업데이트하기 위해서는 변화율이 1이므로 단순히 1을 더하면 된다.

▶ 오차 역전파로 가중치와 절편을 더 적절하게 업데이트하기
y에서 y_hat를 뺀 오차의 양을 변화율에 곱하는 방법으로 w를 업데이트한다.
1. 오차와 변화율을 곱하여 가중치 업데이트하기
w과 b가 각각 큰 폭으로 바뀌었음을 확인할 수 있다.

2. 두번째 샘플 x[1]로 오차를 구하고,새로운 w,b로 업데이트

3. 전체 샘플을 반복하기

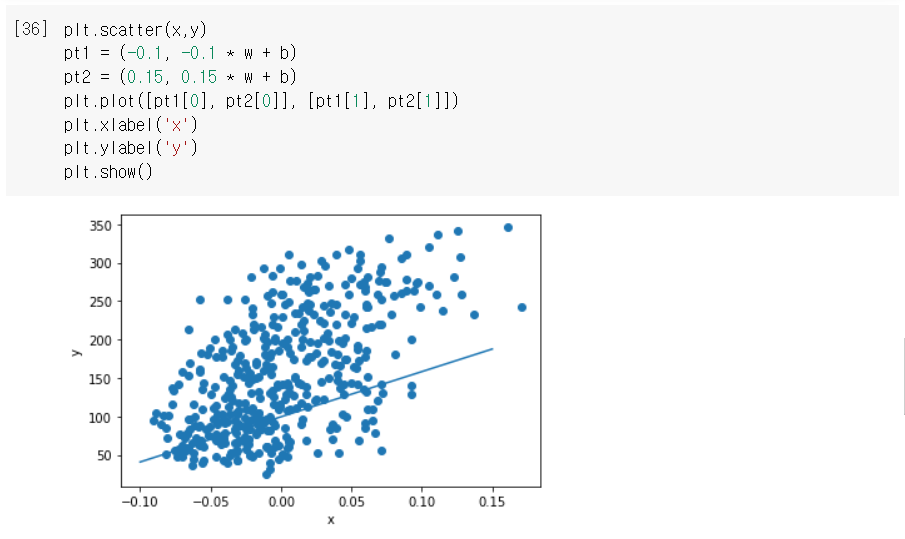
4. 3번 과정을 통해 얻어낸 모델이 전체 데이터 세트를 잘 표현하는지 그래프 그려보기
5. 여러 에포크를 반복하기
* 에포크 : 전체 훈련 데이터를 모두 이용하여 한 단위의 작업을 진행하는 것

100번의 에포크를 반복하여 찾은 w과 b를 이용하여 이 직선을 그래프로 나타내면 다음과 같다.

▷ y^ = 913.6x + 123.4
6. 모델로 예측하기
입력 x에 없었던 새로운 데이터가 발생했을 때 이 데이터에 대해 예측값은 다음과 같다.


'딥러닝,인공지능' 카테고리의 다른 글
| Pytorch - Tensorboard, Learning Rate Schedule, save and load model (0) | 2021.01.28 |
|---|---|
| tensorflow 2.0 - post process & save and load model (0) | 2021.01.27 |
| tensorflow 2.0 - Callbacks (0) | 2021.01.27 |
| tensorflow 2.0 - tf.data (load image & make batch, fit with tf.data) (1) | 2021.01.24 |
| tensorflow2.0 - flow_from_dataframe(dataframe 만들기) (0) | 2021.01.24 |



