
minhui study
04. 데이터 세트 분류, 로지스틱 회귀 본문
04-4 분류용 데이터 세트
분류 문제를 위하여 사이킷런에 포함된 유방암 데이터 세트를 사용하자
유방함 데이터 세트에는 유방암 세포의 특징 10개에 대하여 평균, 표준 오차, 최대 이상치가 기록되어 있다.
여기서 우리가 해결해야 할 문제는 유방암 데이터 샘플이 악성 종양인지 혹은 정상 종양인지를 구분하는 이진 분류 문제이다.
| 의학 | 이진 분류 | |
| 좋음 | 양성 종양(정상 종양) | 음성 샘플 |
| 나쁨 | 악성 종양 | 양성 샘플 |
유방암 데이터 세트 준비하기
(1) load_breast_cancer()함수 호출하기
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
(2) 입력 데이터 확인하기
cancer의 data와 target을 살펴보면 우선 cacer에는 569개의 샘플과 30개의 특성이 있다는 것을 알 수 있고, 이 중에 처음 3개의 샘플을 출력해보면 다음과 같다.
print(cancer.data.shape, cancer.target.shape)
# (569, 30) (569,)
cancer.data[:3]
(3) 박스 플롯으로 특성의 사분위 관찰하기
▷ 박스 플롯이란
: 1사분위와 3사분위 값으로 상자를 그린 다음 그 안에 2사분위(중간값)을 표시한다. 그런 다음 1사분위와 3사분위 사이 거리의 1.5배만큼 위아래 거리에서 각각 가장 큰 값과 가장 작은 값까지 수염을 그린다.

plt.boxplot(cancer.data)
plt.xlabel('feature')
plt.ylabel('value')
plt.show()
박스 플롯을 보면 4, 14, 24번째 특성이 다른 특성보다 값의 분포가 훨씬 크다는 것을 알 수 있다.
(4) 눈에 띄는 특성 살펴보기
cancer.feature_names[[3,13,23]]
# array(['mean area', 'area error', 'worst area'], dtype='<U23')결과를 보면 모두 넓이와 관련된 특성이다.
(5) 타깃 데이터 확인하기
타깃 데이터가 어떻게 이루어져 있는지 확인하기 위해 넘파이 unique()함수를 사용한다.
np.unique(cancer.target, return_counts=True)
# (array([0, 1]), array([212, 357]))위 결과값에서 [0,1]은 cancer.target이 0과 1로 이루어져 있다는 것을 의미하고, [212, 357]은 0(false)가 212개, 1(true)가 357개 있다는 것을 의미한다. 212개의 음성클래스(정상 종양), 357개의 양성클래스(악성 종양)
(6) 훈련 데이터 세트 저장하기
x = cancer.data
y = cancer.target
04-5 로지스틱 회귀를 위한 뉴런 만들기
모델 성능 평가를 위해 훈련세트와 테스트 세트 분류
훈련 데이터 세트를 훈련 세트와 테스트 세트로 나누는 규칙
|

훈련 세트와 테스트 세트로 나누기
훈련 데이터 세트를 훈련세트와 테스트 세트로 나눌 때 양성, 음성 클래스가 훈련 세트와 테스트 세트에 고르게 분포되어야 한다.

(1) train_test_split() 함수로 훈련 데이터 세트 나누기
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, stratify=y, test_size=0.2, random_state=42)train_test_split() : 기본 훈련 세트 75%, 테스트 세트 25%
- sratify = y : 훈련 데이터를 나눌 때 클래스 비율 동일하게 만들고, 일부 클래스 비율이 불균형할 경우 stratify를 y로 지정해야 한다.
- test_size = 0.2 : 기본 훈련 데이터세트를 75:25 비율로 나누는데, 필요한 경우 이 비율을 조정할 수 있다. 여기서는 입력된 데이터 세트의 20%를 테스트 세트로 나누기 위해 test_size에 0.2 전달하였다.
- random_state = 42 : train_test_split()는 무작위로 데이터 세트를 섞은 다음 나누는데 나눈 결과가 항상 일정하도록 난수를 42로 초기화 한다.
(2) 결과 확인하기
print(x_train.shape, x_test.shape)
#(455, 30) (114, 30)shape 속성을 이용해 확인해보면 각각의 훈련 세트와 테스트 세트는 4:1의 비율(455, 114)로 잘 나누어졌다.
(3) unique()함수로 훈련 세트의 타깃 확인하기
np.unique(y_train, return_counts=True)
# (array([0, 1]), array([170, 285]))훈련 세트 타깃 안에 있는 클래스의 개수는 전체 훈련 데이터 세트의 클래스 비율과 거의 비슷한 구성인 것을 확인할 수 있다.
로지스틱 회귀 구현
class LogisticNeuron:
def __init__(self): # 가중치와 절편을 미리 초기화하지 않는다.
self.w = None
self.b = None
def forpass(self, x):
z = np.sum(x * self.w) + self.b # 직선 방정식을 계산
return z
# np.sum(x*self.w)는 넘파이 배열 안의 모든 요소들을 다 더하는 것
def backprop(self, x, err):
w_grad = x * err # 가중치에 대한 그래디언트를 계산
b_grad = 1 * err # 절편에 대한 그래디언트를 계산
return w_grad, b_grad
def fit(self, x, y, epochs=100):
self.w = np.ones(x.shape[1]) # 가중치를 초기화한다.
self.b = 0 # 절편을 초기화한다.
for i in range(epochs): # epochs만큼 반복한다.
for x_i, y_i in zip(x, y): # 모든 샘플에 대해 반복한다.
z = self.forpass(x_i) # 정방향 계산
a = self.activation(z) # 활성화 함수 적용
err = -(y_i - a) # 오차 계산
w_grad, b_grad = self.backprop(x_i, err) # 역방향 계산
self.w -= w_grad # 가중치 업데이트
self.b -= b_grad # 절편 업데이트
def activation(self, z):
z = np.clip(z, -100, None) # 안전한 np.exp() 계산을 위해
a = 1 / (1 + np.exp(-z)) # 시그모이드 계산
return a
def predict(self, x):
z = [self.forpass(x_i) for x_i in x] # 선형함수(정방향 계산)
a = self.activation(np.array(z)) # 활성화 함수 적용
return a > 0.5 # 계단 함수 적용init()
데이터 특성이 많아 가중치와 절편을 미리 초기화 하지 않는다.
forpass()
가중치와 입력 특성 곱을 모두 더하기 위해 np.sum() 함수 이용한다.
fit()
활성화 함수 activation를 적용시키고, 역방향 계산에서 로지스틱 손실 함수의 도함수를 적용한다.
가중치는 np.ones()함수를 이용하여 간단히 1로 초기화 하고, 절편은 0으로 초기화한다.
* np.ones() 함수는 입력된 매개 변수와 동일한 크기의 배열을 만들고 값을 모두 1로 채운다.
activation()
자연 상수의 지수 함수를 계산하는 np.exp()로 시그모이드 함수를 구현하였다.
predict()
예측값은 선형함수, 활성화 함수, 임계 함수 순서로 통과시키면 구현할 수 있다.
z = [self.forpass(x_i) for x_i in x]
: z의 계산으로 파이썬의 리스트 내포 문법을 사용했다. 리스트 내포란 대괄호 [] 안에 for문을 삽입하여 새 리스트를 만드는 간결한 문법이다. x의 행을 하나씩 꺼내어 forpass()에 적용하고 그 결과를 이용해 새 리스트(z)로 만드는 것이다.
z는 곧바로 넘파이 배열로 바꾸어 activation()메소드에 전달한다.
→ 이제 z는 파이썬 리스트가 되었는데 a를 만들기 전에 np.array를 이용하여 z를 넘파일 배열로 바구고 활성화 함수에 넣으면 a는 상황에 따라 손실 함수를 최소화하기 위해 1 또는 0이 된다.
return a > 0.5 을 넣어주면서 a가 0.5보다 클 때는 true를 아닐 경우는 false를 얻도록 만든다.
로지스틱 회귀 모델 훈련시키기
neuron = LogisticNeuron() # 여태껏 만들었던 class LogisticNeuron을 neuron이라는 객체에 저장한다.
neuron.fit(x_train, y_train) #x_train과 y_train을 이용하여 훈련을 시킨다.
np.mean(neuron.predict(x_test) == y_test)
# 0.8245614035087719
-> 올바르게 예측한 샘플의 비율을 출력하면 대략 0.82이므로 82% 정도의 정확도가 나온 것이다.
04-6 로지스틱 회귀 뉴런으로 단일층 신경망 만들기
일반적인 신경망의 모습
아래 그림에서 작은 원으로 표시된 활성화 함수는 은닉층과 출력층의 한 부분으로 간주한다.
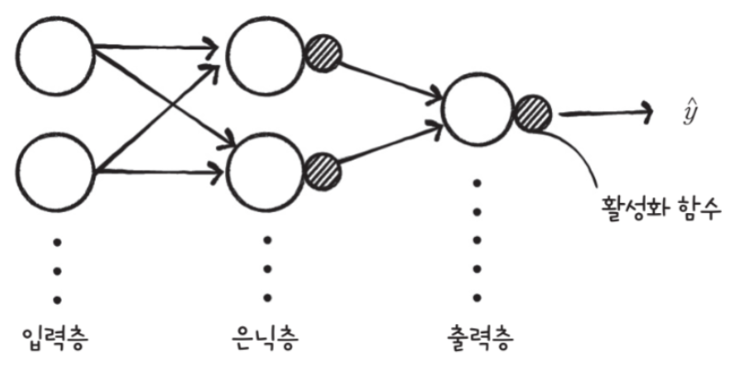
직전에 했던 로지스틱 회귀는 단일층 신경망으로서 은닉층은 없고 입력층과 출력층으로 이루어져 있다.

여러 가지 경사 하강법
- 확률적 경사 하강법
- 샘플 데이터 1개마다 그레디언트를 계산하여 가중치를 업데이트하므로 계산 비요은 적은 대신 가중치가 최적값에 수렵하는 과정이 불안정하다. - 배치 경사 하강법
- 전체 룬련 세트를 사용하여 한 번에 그레이디언트를 계산하므로 가중치가 최적값에 수렴하는 과정은 안정적이지만 그만큼 계산 비용이 많이 든다. - 미니 배치 경사 하강법
- 위의 둘의 장점을 절층한 것이 미니 배치 경사 하강법이다.
- 확률적 경사 하강법보다는 매끄럽고 배치 경사 하강법보다는 덜 매끄러운 그래프가 그려진다.
- batch 크기를 작게 하여 처리함
단일층 신경망 구현
class SingleLayer:
def __init__(self):
self.w = None
self.b = None
self.losses = []
def forpass(self, x):
z = np.sum(x * self.w) + self.b # 직선 방정식을 계산합니다
return z
def backprop(self, x, err):
w_grad = x * err # 가중치에 대한 그래디언트를 계산합니다
b_grad = 1 * err # 절편에 대한 그래디언트를 계산합니다
return w_grad, b_grad
def activation(self, z):
z = np.clip(z, -100, None) # 안전한 np.exp() 계산을 위해
a = 1 / (1 + np.exp(-z)) # 시그모이드 계산
return a
def fit(self, x, y, epochs=100):
self.w = np.ones(x.shape[1]) # 가중치를 초기화합니다.
self.b = 0 # 절편을 초기화합니다.
for i in range(epochs): # epochs만큼 반복합니다
loss = 0
# 인덱스를 섞습니다
indexes = np.random.permutation(np.arange(len(x)))
for i in indexes: # 모든 샘플에 대해 반복합니다
z = self.forpass(x[i]) # 정방향 계산
a = self.activation(z) # 활성화 함수 적용
err = -(y[i] - a) # 오차 계산
w_grad, b_grad = self.backprop(x[i], err) # 역방향 계산
self.w -= w_grad # 가중치 업데이트
self.b -= b_grad # 절편 업데이트
# 안전한 로그 계산을 위해 클리핑한 후 손실을 누적합니다
a = np.clip(a, 1e-10, 1-1e-10)
loss += -(y[i]*np.log(a)+(1-y[i])*np.log(1-a))
# 에포크마다 평균 손실을 저장합니다
self.losses.append(loss/len(y))
# np.random.permutation 사용하여,인덱스를 섞어 훈련시킨다.(매 에포크마다 훈련 세트의 샘플 순서를 섞어서 사용)
# 샘플마다 손실 함수를 계산하고 그 결과값을 다 더하여 샘플 개수로 나눈다.
# 이때 activation으로 계산한 a를 np.log에 적용시키기 위해 조정을 하고, 안전한 로그 계산을 위해 clip 시켜준 후 계산한다.
# (손실 함수의 결과값 저장 기능 추가)
def predict(self, x):
z = [self.forpass(x_i) for x_i in x] # 정방향 계산
return np.array(z) > 0 # 스텝 함수 적용
def score(self, x, y):
return np.mean(self.predict(x) == y)
##시그모이드 함수의 출력값은 0~1사이의 확률값이고, 양성 클래스를 판단하는 기준은 0.5 이상이다.
##predict()에는 굳이 시그모이드 함수를 사용자 않아도 되므로, predict에서 로지스틱 함수를 적용하지 않고
##z 값의 크기만 비교하여 결과물에 반환함
단일층 신경망 훈련하기
1. 단일층 신경망 훈련하고 정확도 출력하기

에포크마다 훈련 세트를 무작위로 섞어 손실 함수의 값을 줄였기 때문에 성능이 좋아졌다.
2. 손실함수 누적값 확인하기
로지스틱 손실 함수의 값이 에포크가 진행됨에 따라 감소하고 있음을 확인할 수 있었다.

04-7 사이킷런으로 로지스틱 회귀를 수행하기
1. 로지스틱 손실 함수 지정하기
from sklearn.linear_model import SGDClassifier
sgd = SGDClassifier(loss='log', max_iter=100, tol=1e-3, random_state=42)- loss 매개변수에 손실 함수로 log 지정
- max_iter를 통해 반복 횟수를 100으로 지정하고 반복 실행했을 때 결과를 동일하게 재현하기 위해 random_state를 통해 난수 초깃값을 42로 선정한다.
- 반복할 때 마다 로지스틱 손실 함수의 값이 tol값 만큼 감소되지 않으면 반복을 중단하도록 설정한다. 만약 tol 설정 하지 않으면 max_iter의 값을 늘리라는 경고가 발생한다.
2. 사이킷런으로 훈련하고 평가하기
fit()메서드로 훈련하고 score로 정확도 계산한다.
sgd.fit(x_train, y_train)
sgd.score(x_test, y_test)
# 0.8333333333333334
3. 사이킷런으로 예측하기
사이킷런은 입력데이터로 2차원 배열만 받아드리고, 배열의 슬라이싱으로 테스트 세트에서 10개의 샘플만 뽑아 예측한다.
sgd.predict(x_test[0:10])
# array([0, 1, 0, 0, 0, 0, 1, 0, 0, 0])
< 참고 자료 >
Do it! 딥러닝 입문 - 박해선 지음
'딥러닝,인공지능 > Do it! 딥러닝입문' 카테고리의 다른 글
| 05. 훈련노하우 - 규제 방법과 교차 검증 (0) | 2021.05.05 |
|---|---|
| 05. 훈련노하우 - 검증 세트와 전처리 과정, 과대/과소 적합 (0) | 2021.05.05 |
| 04. 분류하는 뉴런 만들기 - 이진 분류(3) (0) | 2021.04.04 |
| 04. 분류하는 뉴런 만들기 - 이진 분류(1)(2) (0) | 2021.04.04 |
| 03. 선형 회귀와 경사 하강법, 선형 회귀 뉴런 구현 (0) | 2021.04.04 |



