
minhui study
week3(1) - 명령어를 효과적으로 실행하기 위한 기법 본문
1. 주소 지정 방식
- 주소 : 주기억장치에서 데이터가 저장된 위치
- 주소 지정 방식(addressing mode) : 주소를 지정하는 방식
- 유효주소 (Effective Address) : 데이터가 저장된 기억장치의 실제주소를 유효주소라고 한다.
주어진 주소지정방식에 의해 얻어진 데이터의 기억장치 주소를 가르킨다.

- EA : 명령어 수행에 필요한 데이터가 저장되어 있는 기억장치의 실제 주소를 말한다.
- A : 명령어 내의 오퍼랜드 필드가 기억장치를 나타내는 경우 주소 필드의 내용
- R : 명령어 내의 오퍼랜드 필드가 레지스터를 나타내는 경우에 명령어 내의 레지스터 번호
- (A) : 기억장치 A에 저장되어 있는 데이터를 나타낸다.
- (R) : 레지스터 R에 저장되어 있는 데이터를 나타낸다.
① 직접 주소지정 방식(direct addressing mode)
: 기장 일반적인 개념의 간단한 주소 방식으로 오퍼랜드 필드의 내용이 유효 주소가 되는 방식이다.
: 프로그램의 주소와 기억장티의 주소가 동일한 주소 지정 방식으로 한 번의 메모리 참조만이 있을 뿐 특별한 연산은 없다.
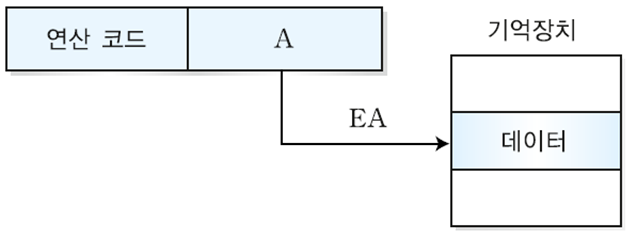
EA = A
( 유효 주소 = 기억장치 주소 )
→ 장점
- 명령어 형식이 간단하고, 데이터 인출을 위해 오퍼랜드에 저장된 해당 주소의 기억장치에 한번만 액세스한다.
→ 단점
- 주소공간이 제한되어 많은 수의 주소를 지정할 수 없다.
- 연산 코드를 제외하고 남은 비트들이 주소 비트로 사용되기 때문에 지정할 수 있는 기억장소의 수가 제한된다.
ex) 16비트의 명령어 중에서 연산코드 길이가 4비트인 경우, 오퍼랜드 필드의 길이는 16-4 = 12비트이므로,
직접 주소지정 방식을 통하여 지정할 수 있는 메모리의 크기는 2^12 = 4096개이다.
② 간접 주소지정 방식(indirect addressing mode)
: 직접 주소 방식의 문제점을 해결하기 위한 것으로 오퍼랜드 필드의 내용이 유효 주소의 주소가 되는 방식이다.
오퍼랜드 필드가 메모리 내의 주소를 참조하여 그 주소로부터 유효 번지를 계산하여 메모리에 접근하는 방식으로 두 번의 메모리 엑세스가 일어난다.

EA = (A)
유효 주소 = 기억장치 A번지의 내용
- 두 번의 기억장치 액세스가 필요하다.
-> 첫 번째는 유효주소가 저장된 곳에 액세스한다.
-> 두 번째는 유효주소에 액세스하여 실질적인 데이터를 얻는 것이다.
→ 장점
- 최대 기억장치 용량 : CPU가 한 번에 액세스할 수 있는 단어의 길이에 의하여 결정이 된다.
N워드 -> 2의 N승의 주소 공간을 활용할 수 있다.
( * 워드 : CPU가 한번에 읽고 쓸 수 있는 비트수 )
- 기억장치의 구조 변경 등을 통해 확장이 가능하다.
- 명령어의 주소 필드 길이가 짧고 제한되어 있어도 긴 주소에 접근이 가능하다.
즉, 짧은 길이를 가진 명령어로 큰 용량의 기억 장소의 주소를 지정할 수 있다.
→ 단점
- 실행 사이클 동안 두 번의 기억장치 액세스가 필요하다. 즉, 주소에 대한 내용을 구한 후에 그 내용을 다시 한번 주소로 이용해서 내용을 구해야 하기 때문이다. ( 직접 주소 지정 방식은 액세스 1번만 필요하다. )
- 명령어 형식에서도 주소지정 방식을 표시하는 간접비트(I) 필드가 필요하다.
* I = 0 : 직접 주소지정 방식, I = 1 : 간접 주소지정 방식

③ 레지스터 주소지정 방식(register addressing mode)
: 연산에 사용할 데이터가 레지스터에 저장되어 있는 방식으로 오퍼랜드 부분이 레지스터 번호를 나타내며 유효주소는 레지스터 번호이다. 주소 필드가 주 기억장치 주소가 아닌 레지스터를 가르킨다.

EA = R
(유효 주소 = 레지스터 번호)
→ 장점
- 비트 수가 적어도 되며, 데이터 인출을 위하여 기억장치에 액세스할 필요가 없다.
- 주소 필드가 레지스터 번호를 나타내므로 비트수가 적어도 되며, 데이터 인출을 위해 기억장치에 접근할 필요가 없다.
→ 단점
- 데이터를 저장할 수 있는 공간이 CPU내부의 레지스터로 제한된다.
④ 레지스터 간접 주소지정 방식(register-indirect addressing mode)
: 오퍼랜드 필드가 레지스터 번호를 나타내며, 해당 레지스터에 저장된 내용이 유효주소이다. 레지스터의 크기에 따라 지정되어지는 기억장치의 주소의 범위가 지정된다.
ex) 사용되어지는 레지스터의 길이가 16비트라면 2^16 비트까지의 주소를 지정할 수 있다.
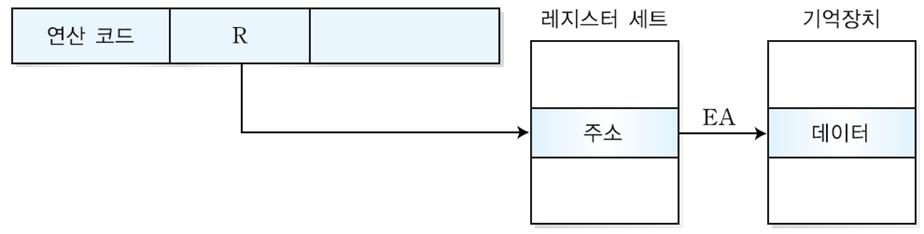
EA = (R)
(유효 주소 = 레지스터에 저장된 내용)
→ 특징
- 레지스터의 길이에 따라 주소지정 영역이 결정된다.
- 레지스터의 길이 : 16비트 -> 주소지정 영역 : 2^16비트
→ 기억장치 액세스
- 간접 주소 지정 방식 : 기억장치에 두 번 액세스한다.
- 레지스터 간접 주소지정 방식 : 기억장치에 한 번만 액세스한다.
→ 장점
- 많은 주소 공간을 활용할 수 있다.
- 사용되어지는 레지스터의 길이에 따라 데이터 저장 영역이 확장되어질 수 있다.
→ 단점
- 간접 주소 방식보다는 메모리 참조(주기억장치 Access)가 적게 일어나지만 여분의 메모리 참조(레지스터 Access)가 필요하다.
- 레지스터의 크기에 따라 지정되어지는 기억장치의 주소의 범위가 제한되어 질 수 있고, 레지스터 지정 방식과는 달리 데이터 인출을 위하여 한 번의 기억장치 액세스가 필요하다.
⑤ 변위 주소지정 방식(displacement addressing mode)
: 직접 주소지정 방식과 레지스터 간접 주소지정 방식을 조합한 방식이다. 최종적인 유효 지정 주소는 기준 주소값과 변위 값을 더한 값이 된다.

ER = (R) + A
(유효 주소 = R이 가리키는 레지스터의 내용 + 변위 값 A)
-> 오퍼랜드 : 레지스터 번호필드와 변위 값 필드로 구성된다.
-> 오퍼랜드의 두 필드의 조합으로 유효 주소가 생성된다.
-> 사용하는 레지스터의 따른 종류
1) 상대 주소지정 방식(Relative Addressing Mode) : 프로그램 카운터(PC)를 사용하는 변위 주소지정 방식으로 주로 분기 명령어에서 사용된다. 변위 값 A는 양수 혹은 음수 값을 가질 수 있다.

EA = (PC) + A
유효 주소 = 프로그램 카운터의 내용 + 기억장치 주소
→ 장점 : 사용되어지는 레지스터가 PC로 묵시적으로 정해지므로 명령어 형식에서 레지스터를 나타내는 필드가 필요하지 않다.
→ 단점 : 변위(A)의 길이 혹은 범위가 오퍼랜드 필드의 비트 수에 제한을 받는다.
ex) 450번지에 저장된 JUMP 명령어가 인출된 후에 PC내용이 451이 된 경우
-> A = +21인 경우 : 분기 목적지 주소는 472(= 451 + 21)번지
-> A = -21인 경우 : 분기 목적지 주소는 401(= 451 - 50) 번지
2) 인덱스 주소지정 방식(Indexed Addressing Mode) : 인덱스 레지스터 사용하는 변위 주소지정 방식

EA = (IX) + A
유효 주소 = 인덱스 레지스터의 내용 + 기억장치 주소
- 인덱스 레지스터 : 인덱스 값을 저장하는 특수 레지스터이다.
- 인덱스 레지스터(IX)의 내용과 변위 A를 더하여 유효 주소를 결정한다.
- 명령어가 실행될 때마다, 인덱스 레지스터의 내용이 자동적으로 증가 혹은 감소한다.
- 명령어가 실행되면 다음 두 연산이 연속적으로 수행된다.
EA = (IX) + A, IX ← IX + 1
- 일반적으로 인덱스 주소 지정 방식은 데이터의 배열 연산에 유용하고 인덱스의 내용은 데이터 배열의 시작으로부터 배열 내의 데이터까지의 위치를 나타낸다.
3) 베이스 레지스터 주소지정 방식(Base-Register Addressing Mode) : 베이스 레지스터를 사용한다.

EA = (BR) + A
유효 주소 = 베이스 레지스터의 내용 + 기억장치 주소
- 베이스 레지스터(BR)의 내용과 변위 A를 더하여 유효 주소를 결정한다.
- 베이스 레지스터 주소지정 방식은 주로 기억장치 내의 프로그램 위치를 지정하는데 사용된다.
2. 명령어 파이프라인
- 하나의 명령어가 실행되는 도중에 다른 명령어 실행을 시작하는 방법으로 동시에 여러 개의 명령어를 실행하는 방법
- 하나의 명령어를 여러 단계로 나누어서 처리할 수 있기 때문에 처리 속도를 향상시킬 수 있다.
→ 종류
① 2-단계 명령어 파이프라인
: 명령어를 실행하는 하드웨어를 인출 단계(fetch stage)와 실행단계(execute stage)라는 두 개의 독립적인 파이프라인 모듈로 분리하여서 수행하는 방법
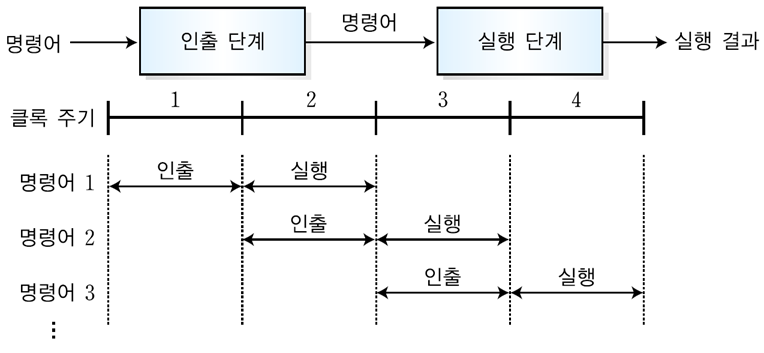
- 첫 번째 명령어의 실행은 두 클록 주기만에 종료되지만, 두 번째 명령어는 그 때부터 한 클록 후에 실행이 완료된다.
그리고 그 다음 명령어들도 각각 한 클록씩만 지나면 실행이 종료된다.
② 4-단계 명령어 파이프라인
: 명령어 인출, 명령어 해독, 오퍼랜드 인출, 명령어 실행의 4단계로 구성된 파이프라인

- 명령어 인출(IF, Instruction Fetch) 단계 : 명령어를 기억장치에서 인출하는 과정으로 프로그램 카운터에서 제시된 기억장치주소에 근거해서 명령어를 인출하여 명령어 레지스터로 이동시키는 단계이다.
- 명령어 해독(ID, Instruction Decode) 단계 : 명령어 해독기를 이용하여 첫 번째 단계에서 인출된 명령어를 해석
- 오퍼랜드 인출(OF, Operand Fetch) 단계 : 기억장치에서 오퍼랜드를 인출하는 단계로 오퍼랜드는 피연산자 부분으로 연산에 사용될 변수나 데이터를 지칭함
- 실행(EX, Execute) 단계 : 명령어에서 지정된 연산을 수행하는 단계
-> 파이프라인 클록은 처리 시간이 가장 오래 걸리는 단계를 기준으로 정해져야 한다.
③ 6-단계 명령어 파이프라인
: 명령어 인출, 명령어 해독, 오퍼랜드 계산, 오퍼랜드 인출, 명령어 실행, 오퍼랜드 저장의 6단계로 구성된 파이프라인
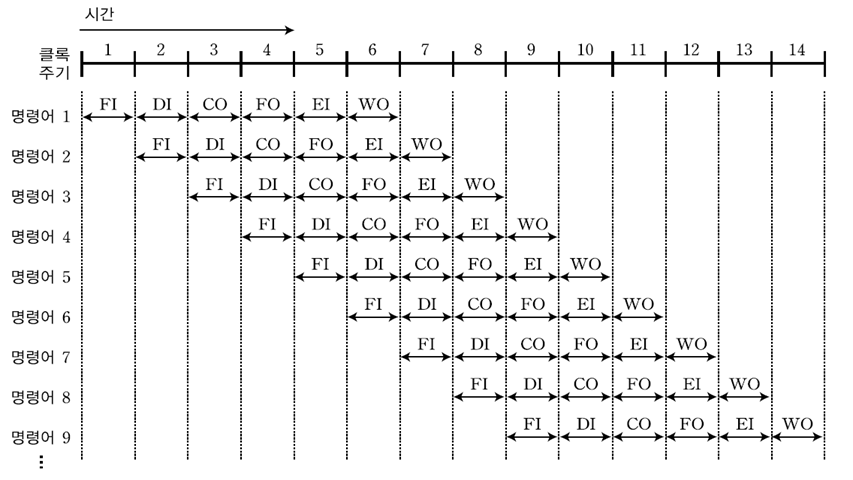
- FI(Fetch Instruction) 단계 : 명령어 인출단계
- DI(Decode Instruction) 단계 : 명령어 해독단계
- CO(Calculate Operand) 단계 : 오퍼랜드 계산 단계
-> 간접 주소 또는 변위주소 지정방식으로 유효주소를 찾는 계산이 필요하다.
- FO(Fetch Operand) 단계 : 오퍼랜드 인출단계
- EI(Execute Instruction) 단계 : 명령어 실행단계
- WO(Write Operand) 단계 : 오퍼랜드 저장 단계, 연산된 결과를 저장하는 단계
* 파이프 라인에 의한 속도 향상
- 명령어 실행 시간 계산
k : 파이프라인의 단계 수
N : 실행할 명령어들의 수
각 파이프라인의 단계 : 한 클록 주기씩 소요됨
T : 파이프라이을 적용했을 때 N개이 명령어를 실행하는데 소요되는 시간
T = k + (N-1)
T' : 파이프라인을 적용하지 않았을 때, N개의 명령어를 실행하는데 소요되는 시간
T '= k * N
- 첫 번째 명령어를 실행하는 데는 k주기가 걸리고 나머지 (N-1)개의 명령어들은 각각 한주기씩만 소요된다. 만약 파이프라인이 되지 않았다면 N개의 명령어들을 실행하는 데는 k*N주기가 걸리므로 파이프라이닝을 이용함으로써 얻을 수 있는 속도 향상은 다음과 같은 식으로 구할 수 있다.
T' / T = (k * N) / (K + (N - 1))
ex) k = 4
N = 10
파이프라인 클록 = 1MHz (각 파이프라인 단계에서의 소요시간 = 1㎲ )
T = 4 + (10 - 1) = 13㎲
T' = (4 * 10) = 40㎲
파이프라이닝에 의한 속도 향상 : T' / T = 40/13 ≒ 3.08배
3. 인터럽트
: CPU가 현재 실행 중인 프로그램의 처리를 강제적으로 중단시키고, 특정 주소에 위치한 프로그램을 수행하는 것
→ 동작 원리
- 인터럽트 서비스 루틴(ISR, Interrupt Service Routine) : 인터럽트를 처리하기 위해 실행되는 프로그램 루틴
- 인터럽트가 시작되면, 현재 실행 중인 프로그램의 중요 데이터는 주기억장치에 저장되고 실행중인 프로그램은 중단된다.
- 중단된 프로그램은, ISR이 처리하는 프로그램이 종료된 후에, 실행된다.
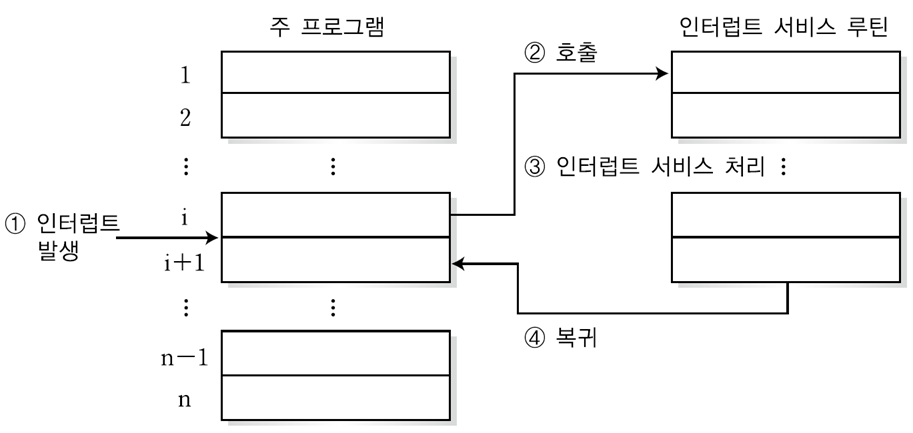
→ 인터럽트 과정
- 현재 실행 중인 프로세스는 system call을 통해 인터럽트를 발생시킨다.
- CPU는 현재 진행 중인 기계어 코드를 완료한다.
- 현재까지 수행 중이었던 상태를 해당 프로세스의 Process Control Block에 저장한다.
- PC에 다음에 실행할 명령의 주소를 저장한다.
- ISR 주소값을 얻어 ISR로 점프하여 루틴을 실행한다.
- 해당 코드를 실행한다.
- 해당 일을 다 처리하면, 대피시킨 레지스터를 복원한다.
- ISR의 끝에 IRET(Interrupt return) 명령어에 의해 인터럽트가 해제 된다.
- IRET 명령어가 실행되면 대피시킨 PC값을 복원하여 이전 실행 위치로 복원한다.
→ 기계착오 인터럽트
: 프로그램을 실행하는 도중, 갑작스런 정전이나 컴퓨터 자체 내에서 기계적인 문제로 인해 발생하는 인터럽트
→ 슈퍼바이저 호출 인터럽트(Supervisor Call Interrupt)
: 슈퍼바이저 호출(SVC) 명령어를 사용하여 운영체제에 서비스를 요청할 때 발생하는 인터럽트
* SVC(supervisor call)는 프로세서에게 컴퓨터 제어권을 운영체계 수퍼바이저 프로그램에 넘길 것을 지시하는 프로세서 명령어이다.
→ 외부 인터럽트(External Interrupt)
: 오퍼레이터(operator)나 타이머(timer)에 의해 의도적으로 프로그램이 중단된 경우 발생하는 인터럽트
→ 입출력 인터럽트(I/O Interrupt)
: 입출력의 종료나 오류에 의해 CPU의 기능이 요청되는 경우 발생하는 인터럽트
ex) I/O제어기에 의한 프린터 출력, 키보드 입력
→ 프로그램 검사 인터럽트(Program Check Interrupt)
: 프로그램 실행 중 보호된 기억공간 내에 접근하거나 불법적인 명령 수행과 같은 프로그램의 문제로 인해 발생하는 인터럽트
ex) 오버플로우(overflow), 0에 의한 나누기(division by zero)
→ 재시작 인터럽트(Restart Interrupt)
: 오퍼레이터 및 다른 프로세서에 의해서 재시작 명령이 도착하였을 때 발생하는 인터럽트
* 인터럽트 우선 순위
전원 공급 이상 → CPU의 기계적 오류 → 외부 신호에 의한 인터럽트 → 입출력 전송 요청 및 전송 완료/전송 오류
→ 프로그램 검사 인터럽트 → 슈퍼바이저 호출(SVC 인터럽트)

▶ Interrupt Cycle
- 인터럽트 발생을 처리하기 위한 사이클
- CPU가 인터럽트 요구의 존재 여부를 검사하는 과정
- 인터럽트 발생이 없는 경우 : 다음 명령어를 인출하는 사이클 수행
- 인터럽트 요구가 대기 중인 경우:
(1) 인터럽트 사이클에 의해서, 현재 프로그램의 실행을 중단하고 프로그램 상태를 저장
(2) PC를 인터럽트 처리 루틴의 시작 주소로 설정하고 인터럽트를 처리한다.
4. 다중 인터럽트
: 인터럽트 서비스 루틴을 수행하는 동안 또 다른 인터럽트가 발생하는 것
→ 처리 방식
- 순차적인 다중 인터럽트 처리
: 인터럽트 서비스 루틴을 처리하고 있는 도중에는, 새로운 인터럽트 처리요구가 들어오더라도 CPU가 새로운 인터럽트 사이클을 수행하지 않는다.
: 나중에 발생한 인터럽트는 대기상태에서, 현재의 인터럽트에 대한 처리가 종료된 후에 발생한 순서대로 처리된다.
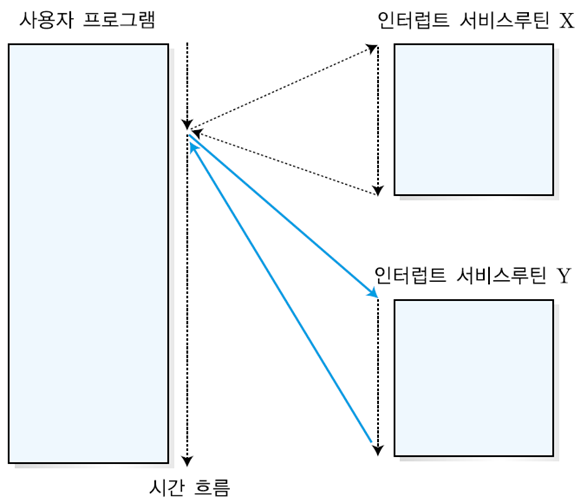
- 우선순위 다중 인터럽트 처리
: 인터럽트의 우선순위를 정한다.
: 우선순위가 낮은 인터럽트가 처리되고 있는 동안에 우선순위가 더 높은 인터럽트가 들어오면, 현재의 인터럽트 서비스 루틴의 수행을 중단하고 새로운 인터럽트를 처리한다.

< 출처 >
강의노트, 디지털논리와 컴퓨터 설계, Harris et al. (조영완 외 번역), 사이텍미디어, 2007, 컴퓨터 구조와 원리 (비주얼 컴퓨터 아키텍처), 신종홍 저, 한빛미디어, 2011
문제 ▼
1. 다음 중 틀린 것을 모두 고르시오
① (A)는 기억장치 A번지의 주소를 나타낸다.
② A는 기억장치를 나타내는 주소이다.
③ R은 레지스터 번호이다.
④ EA는 유효 주소로 기억장치의 실제 주소를 나타내지는 않는다.
2. 다음 그림의 주소 지정 방식을 고르시오
① 직접 주소지정 방식 ② 간접 주소지정 방식 ③ 레지스터 주소지정 방식 ④ 레지스터 간접 주소지정 방식
3. 다음을 계산하시오
(직접 주소지정방식이 해당 주소의 기억장치에 접근하는 횟수 ) + (간접 주소지정방식이 해당 주소의 기억장치에 접근하는 횟수 ) + (레지스터 주소지정방식이 기억장치에 접근하는 횟수) + (레지스터 간접 주소지정 방식이 주기억장치에 접근하는 횟수) = ??
4. 직접 주소지정 방식의 경우 만약 16비트의 명령어 중에서 연산코드의 길이가 8비트인 경우, 오퍼랜드 필드의 길이와
지정할 수 있는 메모리의 크기를 구하시오 ( 제곱으로 나타내도 된다. )
5. 상대 주소지정 방식에서 200번지에 저장된 JUMP 명령어가 인출된 후에 PC 내용이 201이 된 경우 변위 값A(기억장치주소)가 -20인 경우 다음 분기 목적지 주소는?
① 180번지 ② 181번지 ③ 190번지 ④ 221번지
6. 다음 중 2-단계 명령어 파이프라인에 해당되는 단계 2개를 고르시오
① 명령어 해독 단계 ② 인출 단계 ③ 실행 단계 ④ 오퍼랜드 인출 단계
7. 파이프라인의 단계가 6단계이고 실행할 명령어들의 수가 10개라고 할 때 파이프라이닝을 이용함으로써 얻을 수 있는 속도 향상을 구하라
8. 우선순위 다중 인터럽트는 우선순위가 낮은 인터럽트가 처리되고 있는 동안에 우선순위가 더 높은 인터럽트가 들어오면 현재의 인터럽트 서비스 루틴의 수행까지 실행다음 새로운 인터럽트를 처리한다. ( O / X )
9. 다음 중 프로그램 실행 중 보호된 기억공간 내에 접근하거나 불법적인 명령 수행과 같은 프로그램의 문제로 인해 발생하는 인터럽트는 무엇인가?
① 프로그램 검사 인터럽트 ② 입출력 인터럽트 ③ 재시작 인터럽트 ④ 기계 착오 인터럽트 ⑤ 외부 인터럽트
10. 인터럽트 요구가 대기 중인 경우 인터럽트 사이클에 의해서, 현재 프로그램의 실행을 중단하고 프로그램 상태를 저장한다. 그리고 ( )를 인터럽트 처리 루틴의 시작 주소로 설정하고 인터럽트를 처리한다.
빈칸에 들어갈 단어를 쓰시오
답안 ▼
1. ①, ④
: ①(A)는 기억장치 A에 저장되어 있는 데이터를 나타낸다.
④ EA는 유효 주소로 기억장치의 실제 주소를 나타낸다.
2. ④
: 레지스터 간접 주소지정 방식은 오퍼랜드 필드가 레지스터 번호를 나타내며, 해당 레지스터에 저장된 내용이 유효주소이다. 레지스터의 크기에 따라 지정되어지는 기억장치의 주소의 범위가 지정된다.
3. 1 + 2 + 0 + 1 = 4
: 직접 주소지정 방식은 프로그램의 주소와 기억장티의 주소가 동일한 주소 지정 방식으로 한 번의 기억장치의 접근이 일어난다. -> 1
: 간접 주소지정방식은 오퍼랜드 필드가 메모리 내의 주소를 참조하여 그 주소로부터 유효 번지를 계산하여 메모리에 접근하는 방식으로 두 번의 기억장치의 메모리 접근이 일어난다. -> 2
: 레지스터 주소지정 방식은 주소 필드가 주 기억장치 주소가 아닌 레지스터를 가르키며 데이터 인출을 위해 기억장치에 접근할 필요가 없다. -> 0
: 레지스터 간접 주소지정 방식은 기억장치에 한 번, 레지스터에 한번 접근하므로 기억장치 접근 횟수는 1이다.
-> 1
4. 오퍼랜드 필드의 길이는 8비트이고 지정할 수 있는 메모리의 크기는 2^8이다.
문제에서 명령어의 크기를 16비트, 연산코드의 길이를 8비트라고 가정했으므로 A부분 오퍼랜드 필드의 길이는 16-8=8비트이고,그에 따라 직접 주소지정 방식을 통해 지정할 수 있는 메모리의 크기는 2^8이다.
5. ②
: 상대 주소지정 방식은 프로그램 카운터(PC)를 사용하는 변위 주소지정 방식으로 주로 분기 명령어에서 사용된다. 변위 값 A는 양수 혹은 음수 값을 가질 수 있다.
EA = (PC) + A
유효 주소 = 프로그램 카운터의 내용 + 기억장치 주소
따라서 PC 내용이 201로 되었고 A값이 -20이라고 했으므로 답은 201 - 20 = 181번지 이다.
6. ②, ③
: 2-단계 명령어 파이프라인은 명령어를 실행하는 하드웨어를 인출 단계(fetch stage)와 실행단계(execute stage)라는 두 개의 독립적인 파이프라인 모듈로 분리하여서 수행하는 방법으로 오퍼랜드 인출단계와 명령어 해독 단계는 4-단계 명령어 파이프라인에 해당되는 단계들이다.
7. 4배
파이프라이닝을 이용함으로써 얻을 수 있는 속도 향상을 구하기 위해서는 파이프라인을 적용하지 않았을 때, N개의 명령어를 실행하는데 소요되는 시간에서 파이프라이을 적용했을 때 N개이 명령어를 실행하는데 소요되는 시간을 나누어야 한다.
k : 파이프라인의 단계 수
N : 실행할 명령어들의 수
T : 파이프라이을 적용했을 때 N개이 명령어를 실행하는데 소요되는 시간
T' : 파이프라인을 적용하지 않았을 때, N개의 명령어를 실행하는데 소요되는 시간
이라고 했을 때 T'를 구하는 식은 k * N이므로 60이고, T는 k + (N-1)이므로 6 + ( 10 - 1 ) = 15이다.
그러므로 속도 향상은 60 / 15 = 4배라고 할 수 있다.
파이프라인을 적용하지 않았을 때에는 동시에 명령어 처리를 진행할 수 없으므로 단계의 수에 실행할 명령어의 수를 곱해야 한다. 반면에 파이프라인을 적용했을 때는 하나의 명령어가 실행되는 도중에 다른 명령어 실행을 시작하므로 다음의 그림을 보면 일정 시간부터 한 클록 씩 진행될 때마다 명령어가 하나씩 실행 완료가 되는 것을 볼 수 있다. 그 이유는 각 명령어의 FI단계가 한 번에 동시에 실행할 수는 없으므로 명령어1의 FI단계가 끝난 후 명령어2의 FI단계가 진행되기 때문이다.
그러므로 N개의 명령어를 실행하는데 소요되는 시간을 구하는 식이 k + (N - 1)가 된다.
8. X
: 우선순위 다중 인터럽트는 우선순위가 낮은 인터럽트가 처리되고 있는 동안에 우선순위가 더 높은 인터럽트가 들어오면 현재의 인터럽트 서비스 루틴의 수행까지 실행하지 않고 중단한 다음 새로운 인터럽트를 처리한다.
9. ①
: 프로그램 실행 중 보호된 기억공간 내에 접근하거나 불법적인 명령 수행과 같은 프로그램의 문제로 인해 발생하는 인터럽트는 프로그램 검사 인터럽트로 예로 오버플로우나 0에 의한 나누기 등이 있다.
10. PC ( Program Counter )
: 인터럽트 요구가 대기 중인 경우에는 현재 실행 중인 프로그램은 중단하고 그 프로그램의 상태를 저장하는데 이때 PC를 인터럽트 처리 루틴의 시작 주소로 설정하고 인터럽트를 처리한다. 인터럽트가 다 처리되면 PC값을 복원하여 중단시켜놓은 프로그램을 다시 실행한다.
'컴퓨터 구조 > Swing study' 카테고리의 다른 글
| week4 - 명령어 분류와 형식 (0) | 2020.05.26 |
|---|---|
| week3(2) - 메모리 구조와 레지스터 종류 (0) | 2020.05.20 |
| week 2(1) - 컴퓨터 정보의 표현 (0) | 2020.04.13 |
| week 2(2) - 명령어 동작 과정 (0) | 2020.04.13 |
| week 1 - 중앙처리장치(CPU) 구조 및 명령어 동작 과정 (0) | 2020.04.08 |



