
minhui study
week5 - 캐시(Cache) 기억장치 본문
캐시(Cache) 기억장치란?
주기억장치에 저장되어 있는 명령어와 데이터 중의 일부를 임시적으로 복사해서 저장하는 장치이다.
- 명령어와 데이터를 저장하고 인출하는 속도가 주기억장치보다 빠르다. 그래서 중앙처리장치가 주기억장치에서 데이터를 처리하는 것보다 캐시기억장치에서 데이터를 처리하는 속도가 더 빠르다.
- 자주 사용되는 명령들을 저장하고 있다가 중앙처리장치에 빠른 속도로 제공한다.
- 느리게 동작하는 주기억장치와 빠르게 동작하는 중앙처리장치(CPU) 사이에서 속도 차이를 줄여주는 고속완충기억장치이다.
- 캐시기억장치의 용량에 의해 CPU의 가격이 결정된다.

캐시 기억장치가 없는 시스템
□ 동작 원리
①단계 : CPU가 명령어와 데이터를 인출하기 위해서 기억장치에 접근한다.
②단계 : 주기억장치에서 명령어나 필요한 정보를 획득하여 CPU내의 명령어 레지스터 등에 저장한다.

→ 주기억장치는 보조기억장치보다는 빠르지만 중앙처리장치에 비해 매우 느리기 때문에 속도차이를 해결하기 위해 캐시기억장치를 사용하게 되었다.
캐시 기억장치가 있는 시스템
□ 동작 원리
- CPU가 명령어 또는 데이터를 인출하기 위해 주기억장치보다 캐시기억장치를 먼저 조사한다.
- CPU가 명령어를 인출하기 위해 캐시기억자치에 접근하여 그 명령어를 찾았을 때 적중(hit)이라고 하고, 명령어가 존재하지 않아 찾지 못하였을 경우를 실패(miss)로 정의한다.
※ 중앙처리장치는 캐시기억장치에서 원하는 데이터가 있는지 조사하고 없으면 캐시기억장치는 주기억장치로부터 블록단위로 데이터를 가져온다. 그리고 다시 캐시기억장치는 워드 단위로 중앙처리장치로 데이터를 전송한다.
※ 캐시기억장치는 중앙처리장치가 필요로 하는 명령어와 데이터를 가지고 있다가 필요할 때 전송하여 신속하게 처리하는데, 이는 내장형 컴퓨터의 특성인 참조의 지역성 때문에 가능하다.
*참조의 지역성 : 짧은 시간동안 중앙처리장치가 주기억장치를 참조할때, 제한 영역에서만 참조가 이루어지는 것을 의미한다.
*워드 : 하나의 연산을 통해 저장 장치로부터 프로세서의 레지스터에 옮겨놓을 수 있는 데이터 단위이다.
*블록 : 워드가 쌓은 것, 데이터의 뭉치

▷ 캐시 기억장치가 있는 시스템 - miss
→ CPU가 1000번지의 워드가 필요한 경우
: 우선 캐시기억장치가 1000번지의 워드를 저장하고 있는지를 검사하고 1000번지 워드가 캐시기억장치 내에 존재하지 않는다면 실패상태가 된다.

→ 실패상태 처리 방법
①단계 : 주기억장치에서 필요한 정부를 획득하여 캐시기억장치에 전송한다.
②단계 : 캐시기억장치는 얻어진 정보를 다시 중앙처리장치로 전송한다.

▷ 캐시 기억장치가 있는 시스템 - hit
→ CPU가 1002번지의 워드가 필요한 경우
①단계 : 캐시기억장치가 1002번지의 워드를 저장하고 있는지를 검사하고 1002번지 워드가 캐시기억장치 내에 존재한다면 적중상태가 된다.
②단계 : 캐시기억장치에서 얻어진 정보를 중앙처리장치로 전송한다.

□ 캐시(Cache) 기억장치의 동작 원리
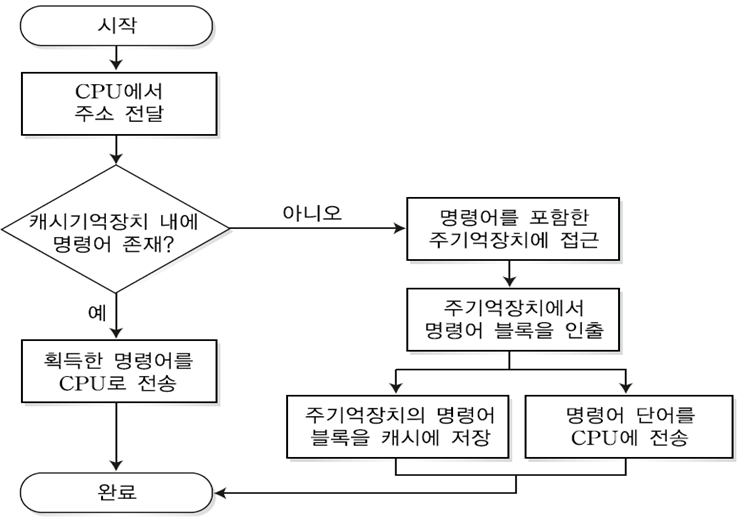
□ 캐시(Cache) 기억장치의 적중률
적중률이란?
: 캐시 기억장치의 성능을 나타내는 척도이다.
: 적중률이 높을수록 데이터 액세스 속도가 향상된다.



□ 캐시(Cache) 기억장치의 설계
주기억장치와 캐시 기억장치 간의 정보 공유는 다음과 같다.

▷ 설계 목표 및 고려사항
1) 캐시 기억장치를 설계함에 있어 공통적인 목표
- 캐시 적중 시 캐시 기억장치로부터 데이터를 읽어오는 시간 단축
- 캐시 실패 시 주기억장치로부터 캐시 기억장치로 데이터를 읽어오는 시간 최소화
- 주기억장치와 캐시 기억장치 사이에 데이터의 일관성을 유지
2) 캐시 기억장치를 설계할 떄 고려 사항
→ 캐시기억 장치의 크기(Size)
: 캐시기억장치의 크기가 클수록, 적중률은 높아지나 평균 접근 시간과 비용이 증가한다.
: 적중률을 향상시키고 평균 접근시간에 대한 저하를 막는 최적의 크기 결정이 필요하다.
: 연구 결과에 의하면 캐시기억장치의 크기로 1K ~ 128K 단어가 최적이라고 알려져 있다.
→ 인출방식(fetch algorithm)
: 주기억장치에서 캐시기억장치로 명령어나 데이터 블록을 인출해오는 방식이다.
| 요구 인출(Demand Fetch) 방식 | 선인출(Prefetch) 방식 |
| - CPU가 현재 필요한 정보만을 주기억장치에서 블록 단위로 인출해 오는 방식 | - CPU가 현재 필요한 정보 외에도 앞으로 필요한 것으로 예측되는 정보를 미리 인출하여 캐시기억장치에 저장하는 방식 - 주기억장치에서 명령어나 데이터를 인출할 때 필요한 정보와 이웃한 위치에 있는 정보들을 함께 인출하여 캐시에 적재하는 방식 |
→ 사상함수(Mapping function)
* 주기억장치의 구조
- 단어(word) : 하나의 주소번지에 저장되는 데이터의 단위
- 블록(block) : k개의 단어로 구성된다.
* 캐시기억장치의 구조
- 슬롯(slot) : 데이터 블록이 저장되는 장소
- 태그(tag) : 슬롯에 적재된 데이터 블록을 구분해주는 정보
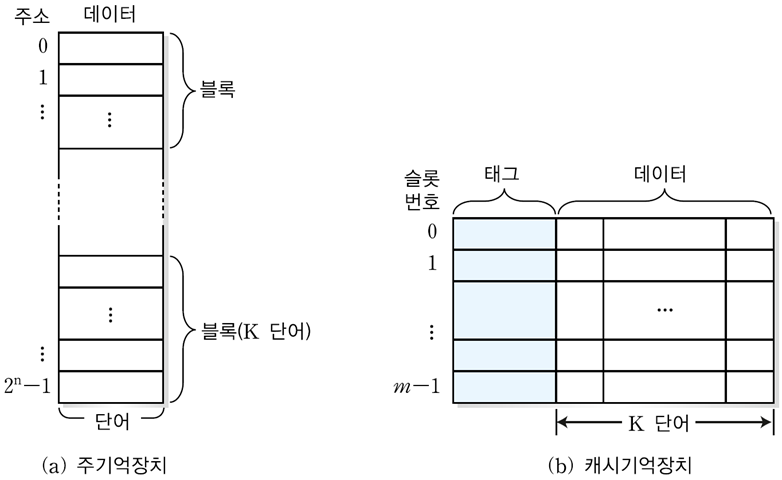
* 사상(mapping)이란?
: 아래 그림에서와 같이 주기억장치와 캐시기억장치 사이에서 정보를 옮기는 것을 사상(mapping)이라고 한다.

→ 캐시 기억장치의 사상방법
1. 직접 사상(direct mapping)
: 아래의 주소 변환을 통해 주기억장치의 데이터 블록을 캐시기억장치에 저장한다.

- 캐시기억장치로부터 데이터 블록 인출을 위해서 데이터 블록의 슬롯번호에 해당하는 슬롯만 검색하면 된다.
- 장점 : 사상 과정이 간단하다.
- 단점 : 동일 슬롯 번호를 갖지만 태그가 다른 데이터 블록들에 대한 반복적인 접근은 적중률을 떨어뜨린다.
[ CPU가 00001번지 블록을 필요로 하는 경우 (1블록 = 1단어)]

[ CPU가 00010번지 블록을 필요로 하는 경우 (1블록 = 1단어)]
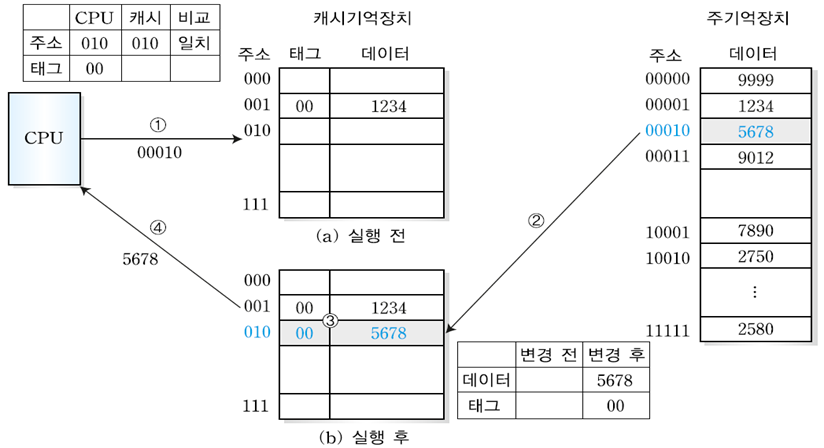
[ CPU가 10001번지 블록을 필요로 하는 경우 (1블록 = 1단어)]

[ CPU가 00010번지 블록을 필요로 하는 경우 (1블록 = 1단어)]
: 00010 번지는 이미 전에 주소 변환을 통해 주기억장치의 데이터 블록을 캐시기억장치에 저장했으므로 이번에는 주기억장치에 접근하지 않고도 원하는 데이터를 가져올 수 있다.

2. 연관 사상(associative mapping)
: 캐시 슬롯번호에 상관없이 주기억장치의 데이터 블록을 캐시 기억장치의 임의의 위치에 저장한다.
: 캐시기억장치로부터 데이터 블록 인출을 위해서 모든 슬롯에 대한 검색이 필요하다.
* 주소 형식


3. 집합 연관 사상(set-associative mapping)
: 직접 사상과 연관 사상 방식을 조합한 방식으로 캐시는 v개의 집합들로 나누어지며, 각 집합들은 k개의 슬록들로 구성된다.
: 직접 사상 방식에 의해, v개의 집합들 중에서 하나의 집합을 선택한다.
: 연관 사상 방식에 의해, 선택한 집합 내에 있는 k개의 슬롯 중에서 하나의 슬롯을 선택한다.
* 주소 형식


→ 교체 알고리즘(Replacement algorithm)
: 캐시기억장치의 모든 슬롯이 데이터로 채워져 있는 상태에서 실패일 때, 주기억장치로부터 새로운 데이터 블록을 캐시기억장치로 옮기기 위해 캐시기억장치의 어느 슬롯 데이터를 제거할지를 결정하는 방식이다.
: 직접사상 -> 교체 알고리즘이 필요 없다.
: 연관&집합 연관 사상 : 교체 알고리즘이 필요하다.
*종류*
| 교체 알고리즘 종류 | 내용 |
| LRU (Least Recently Used) 최소 최근 사용 알고리즘 |
-가장 효과적인 교체 알고리즘으로 집합 연관 사상에서 사용되는 방식이다. |
| LFU (Least Frequently Used) 최소 사용 빈도 알고리즘 | - 적재된 블록들 중에서 인출 횟수가 가장 적은 블록을 교체하는 방식으로 최소 최근 사용 알고리즘이 시간적으로 오랫동안 사용되지 않은 블록을 교체한다. - 최소 사용 빈도 알고리즘은 사용된 횟수가 적은 블록을 교체하는 방식이다. |
| FIFO (First In First Out) 선입력 선출력 알고리즘 | - 가장 먼저 적재된 블록을 우선적으로 캐시기억장치에서 삭제하는 교체방식으로 캐시기억장치에 적재된 가장 오래된 블록이 삭제되고 새로운 블록이 적재된다. - 구현이 용이하나 효율성 보장이 어렵다. |
| RANDOM | - 캐시기억장치에서 임의의 블록을 선택하여 삭제하고 새로운 블록으로 교체하는 방식이다. - 효율성 보장이 어렵다. |
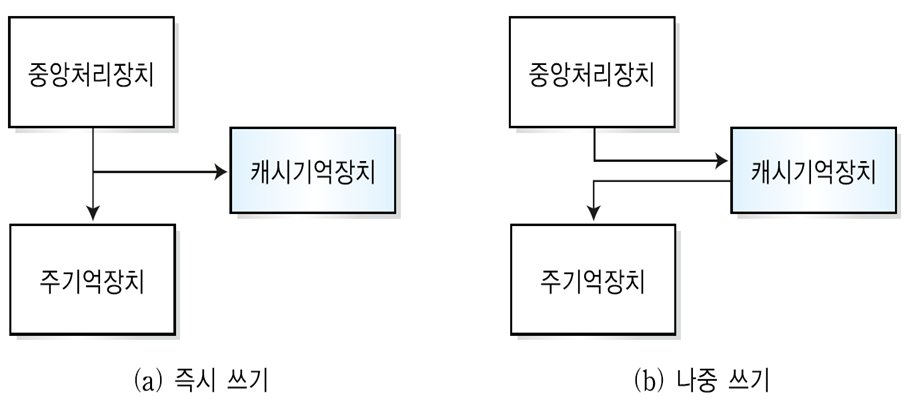
→ 쓰기 정책(Write policy)
즉시 쓰기 방식(Write-though)
CPU에서 생성되는 데이터 블록을 캐시기억장치와 주기억장치에 동시에 기록한다.
장점 : 데이터의 일관성을 쉽게 보장할 수 있다.
단점 : 매번 쓰기 동작이 발생할 때마다, 캐시기억장치와 주기억장치간 접근이 빈번하게 일어나고 쓰기 시간이 길어지게 된다.
나중 쓰기 방식(Write-back)
캐시기억장치에 기록한 후, 기록된 블록에 대한 교체가 일어날 때 주기억 장치에 기록한다.
장점 : 즉시 쓰기 장식과는 달리 주기억장치에 기록하는 동작을 최소화할 수 있다.
단점 : 캐시기억장치와 주기억장치의 데이터가 서로 일치하지 않을 수 있다.
→ 블록 크기(Block size)
- 블록의 크기가 클수록 한번에 많은 정보를 읽어 올 수 있지만 블록 인출 시간이 길어지게 된다.
- 블록이 커질수록 캐시기억장치에 적재할 수 있는 블록의 수가 감소하기 때문에 블록들이 더 빈번히 교체된다.
- 일반적인 블록의 크기 : 4~8 단어가 적당하다.
→ 캐시기억장치의 수(Number of caches)
- 시스템의 성능 향상을 위해서 다수의 캐시기억장치들을 사용하는 것이 보편화되었다.
- 캐시기억장치들을 계층적 구조나 기능적 구조로 설치한다.
< 출처 >
강의노트, 디지털논리와 컴퓨터 설계, Harris et al. (조영완 외 번역), 사이텍미디어, 2007, 컴퓨터 구조와 원리 (비주얼 컴퓨터 아키텍처), 신종홍 저, 한빛미디어, 2011
문제 ▼
1. 다음 중 설명이 옳지 않은 것을 고르시오
① 주기억장치는 보조기억장치보다는 빠르지만 중앙처리장치에 비해 매우 느리기 때문에 속도차이를 해결하기 위해 캐시기억장치를 사용하게 되었다.
② 캐시 기억장치가 있는 시스템 CPU가 명령어 또는 데이터를 인출하기 위해 주기억장치를 먼저 조사한다.
③ CPU가 명령어를 인출하기 위해 캐시기억자치에 접근하여 그 명령어를 찾았을 때 적중(hit)이라고 한다.
④ 명령어가 존재하지 않아 찾지 못하였을 경우를 실패(miss)로 정의한다.
2. 빈 칸을 채우시오
중앙처리장치는 캐시기억장치에서 원하는 데이터가 있는지 조사하고 없으면 캐시기억장치는 주기억장치로부터
( )단위로 데이터를 가져온다. 그리고 다시 캐시기억장치는 ( )단위로 중앙처리장치로 데이터를 전송한다.
3. 다음 중 옳은 방식을 하나만 고르시오
CPU가 현재 필요한 정보 외에도 앞으로 필요한 것으로 예측되는 정보를 미리 인출하여 캐시기억장치에 저장하는 방식 ( 요구 인출 방식 / 선인출 방식 )
4. 주기억장치 접근시간이 400ns이고 캐시기억장치 접근시간이 50ns 일때, 캐시 기억장치의 적중률이 80%인 경우 기억장치 접근 시간을 구하여라 ( )
5. 다음 중 교체 알고리즘이 필요 없는 것을 고르시오
① 직접사상 ② 연관사상 ③집합연관사상
6. 다음 설명 중 옳지 않은 것을 고르시오
① LRU(Least Recently Used)은 가장 효과적인 교체 알고리즘으로 집합 연관 사상에서 사용되는 방식이다.
② LFU(Least Frequently Used)은 최소 사용 빈도 알고리즘은 사용된 횟수가 적은 블록을 교체하는 방식이다.
③ FIFO(First In First Out)은 구현이 용이하고 효율성이 보장된다.
④ RANDOM은 캐시기억장치에서 임의의 블록을 선택하여 삭제하고 새로운 블록으로 교체하는 방식이다.
7. 다음 설명 중 옳은 것을 고르시오
① 블록의 크기가 클수록 한번에 많은 정보를 읽어 올 수 있어 블록 인출 시간이 짧아진다.
② 블록이 커질수록 캐시기억장치에 적재할 수 있는 블록의 수가 증가하기 때문에 블록들이 더 빈번히 교체된다.
③ 즉시 쓰기 방식은 캐시기억장치와 주기억장치의 데이터가 서로 일치하지 않을 수 있다.
④ 즉시 쓰기 방식은 데이터의 일관성을 쉽게 보장할 수 있다.
답안 ▼
1. ②
② : 캐시 기억장치가 있는 시스템 CPU가 명령어 또는 데이터를 인출하기 위해 주기억장치보다 캐시기억장치를 먼저 조사한다.
2. 중앙처리장치는 캐시기억장치에서 원하는 데이터가 있는지 조사하고 없으면 캐시기억장치는 주기억장치로부터 (블록)단위로 데이터를 가져온다. 그리고 다시 캐시기억장치는 (워드) 단위로 중앙처리장치로 데이터를 전송한다.
3. 선인출 방식
| 요구 인출(Demand Fetch) 방식 | 선인출(Prefetch) 방식 |
| - CPU가 현재 필요한 정보만을 주기억장치에서 블록 단위로 인출해 오는 방식 | - CPU가 현재 필요한 정보 외에도 앞으로 필요한 것으로 예측되는 정보를 미리 인출하여 캐시기억장치에 저장하는 방식 - 주기억장치에서 명령어나 데이터를 인출할 때 필요한 정보와 이웃한 위치에 있는 정보들을 함께 인출하여 캐시에 적재하는 방식 |
4. 120ns
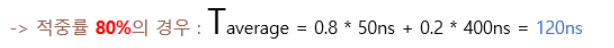
5. ①
: 직접사상 -> 교체 알고리즘이 필요 없다.
: 연관&집합 연관 사상 : 교체 알고리즘이 필요하다.
6. ③
FIFO방식의 특징은 다음과 같다.
- 가장 먼저 적재된 블록을 우선적으로 캐시기억장치에서 삭제하는 교체방식으로 캐시기억장치에 적재된 가장 오래된 블록이 삭제되고 새로운 블록이 적재된다.
- 구현이 용이하나 효율성 보장이 어렵다.
7. ④
① 블록의 크기가 클수록 한번에 많은 정보를 읽어 올 수 있지만 블록 인출 시간이 길어지게 된다.
② 블록이 커질수록 캐시기억장치에 적재할 수 있는 블록의 수가 감소하기 때문에 블록들이 더 빈번히 교체된다.
③ 캐시기억장치와 주기억장치의 데이터가 서로 일치하지 않을 수 있는 것은 나중 쓰기 방식이다.
**추가**
보조기억장치, 입력과 출력, 시스템 버스 문제
▼
1. 보조기억장치에 대한 설명으로 잘못된 것을 모두 고르시오
① 주기억장치의 저장용량 부족을 보완하며, 비휘발성 특징을 이용해 데이터를 영구적으로 저장하는 기억장치이다.
② 보조기억장치의 접근 방법 중 순차적 접근은 데이터가 저장되는 순서에 따라 접근 순서가 결정된다.
③ 보조기억장치의 접근 방법 중 직접 접근에서 접근 시간은 원하는 데이터의 위치와 이전 접근 위치와는 상관이 없다.
④ 보조기억장치의 평가 기준에는 저장 용량, 접근 시간, 전송 시간이 있다.
2. (1) 자기 디스크 기억장치 헤드 중 이동 헤드는 하나의 헤드가 원형평판위를 이동하면서 한 개의 트랙에 읽기와 쓰기를 수행한다. ( O / X )
(2) 자기 디스크 접근 시간은 탐색 시간, 회전 지연과 데이터 전송 시간을 더한 값이다. ( O / X )
3. 입력장치에서 중앙처리장치까지 전달되는 과정을 순서대로 나열하시오
① 외부 데이터 판별 ② 표준 신호로 처리 ③표준 신호 변환
4. 다음 중 직접 기억장치 액세스(DMA) 방식에 옳지 않은 것을 고르시오
① 직접 기억장치 액세스(DMA) 방식은 기억장치와 입출력 모듈 간의 데이터 전송을 별도의 하드웨어인 DMA제어기가 처리하고 중앙처리장치는 개입하지 않는 방식이다.
② DMA방식은 DMA제어기가 모든 입출력 동작을 전담하고 CPU는 전송의 시작과 마지막에만 입출력 동작에 관여한다.
③ 단일버스 분리식 DMA방식은 데이터 전송을 위해 시스템 버스를 한번만 사용한다.
④ 입출력 버스를 이용한 DMA방식은 입출력 버스를 활용해서 데이터 전송 과정에서 시스템 버스를 한번만 사용한다.
5. 주소 버스는 양방향 전송이 가능하다. ( O / X )
답안 ▼
1. ①, ③
① 주기억장치의 저장용량 부족을 보완하며, 비휘발성 특징을 이용해 데이터를 반영구적으로 저장하는 기억장치이다.
③ 직접 접근은 원하는 데이터가 저장된 기억장소 근처로 이동한 다음 순차적 검색을 통해서 원하는 데이터에 접근하는 방법으로 보조기억장치의 접근 방법 중 직접 접근에서 접근 시간은 원하는 데이터의 위치와 이전 접근 위치에 따라 결정된다.
2. (1) X : 이동헤드는 하나의 헤드가 원형평판위를 이동하면서 여러 개의 트랙에 읽기와 쓰기를 수행한다.
(2) O : 자기 디스크를 읽고 쓰는 동작은 다음과 같다.
1. 헤드를 해당 트랙으로 이동 : 탐색 시간
↓
2. 데이터가 포함된 섹터가 회전되어 헤드 아래로 올 때까지 대기 : 회전 지연
↓
3. 데이터 전송 : 데이터 전송 시간
그러므로 디스크 접근 시간 = 탐색 시간 + 회전 지연 + 데이터 전송 시간이다.
3. ① -> ③ -> ②
: 입력장치에서 중앙처리장치까지 전달되는 과정은 입력장치에서 데이터가 들어오면 들어온 외부 데이터를 판별하고 표준 신호로 변환한다. 그리고 표준 신호로 처리한다.
4. ③
③ : 단일버스 분리식 DMA방식은 데이터 전송을 위해 시스템 버스를 두 번씩 사용한다.
5. X
: 주소 버스는 단방향 전송만 가능하다.

'컴퓨터 구조 > Swing study' 카테고리의 다른 글
| week 6 - MIPS 구조 (0) | 2020.06.09 |
|---|---|
| week4 - 명령어 분류와 형식 (0) | 2020.05.26 |
| week3(2) - 메모리 구조와 레지스터 종류 (0) | 2020.05.20 |
| week3(1) - 명령어를 효과적으로 실행하기 위한 기법 (0) | 2020.05.19 |
| week 2(1) - 컴퓨터 정보의 표현 (0) | 2020.04.13 |



