
minhui study
웹 크롤링2(python) 본문
웹툰 크롤러 완성하기
- 해당 웹툰의 제목으로 폴더를 만들고, 그 안에 회차 별로 폴더를 만들어 그 안에 이미지 저장하기
( 이미지 이름은 1.jpg 2.jpg 이런 식으로 저장하였음)
- 그 페이지에 있는 웹툰 전체 회차 가져와서 저장하기(10개)
https://github.com/jeongminhui99/mini/blob/master/webtoon.py
jeongminhui99/mini
Contribute to jeongminhui99/mini development by creating an account on GitHub.
github.com
<전체 코드>
from bs4 import BeautifulSoup
import urllib.request
import os
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36')]
urllib.request.install_opener(opener)
u="https://comic.naver.com/webtoon/detail.nhn?titleId=703846&no=111&weekday=tue"
html = urllib.request.urlopen(u)
result = BeautifulSoup(html.read(), "html.parser")
name=result.findAll("h2")
title=name[1].text[0:4]
print(title)
os.chdir("/Users/user/Desktop/")
os.mkdir(title)
big = "https://comic.naver.com/webtoon/list.nhn?titleId=703846&weekday=tue"
html = urllib.request.urlopen(big)
result = BeautifulSoup(html.read(), "html.parser")
array=[]
list=result.findAll("td", {"class", "title"})
for s in list:
print(s.find("a")['href'])
array.append(s.find("a")['href']) # 전체 리스트 화면에서 각 화의 링크를 리스트에 담기
for i in range(len(array)):
url="https://comic.naver.com"+array[i]
html2 = urllib.request.urlopen(url)
result2 = BeautifulSoup(html2.read(), "html.parser")
search=result2.findAll("img", {"alt" : "comic content"})
name=result2.findAll("meta", {"property" : "og:description"})
for s in name:
print(s['content'])
little=s['content']
os.chdir("/Users/user/Desktop/"+title)
os.mkdir(s['content'])
i=1
for s in search:
picture = s['src']
outpath='C:/Users/user/Desktop/'+title+'/'+little+'/'
outfile=str(i)+'.jpg'
urllib.request.urlretrieve(picture, outpath+outfile)
i += 1
이제 위의 코드를 단계별로 나눠서 실행 결과 화면과 함께 살펴보자
1단계. 웹툰 주제 가져와서 주제 이름의 파일 만들기
from bs4 import BeautifulSoup
import urllib.request # 웹을 열서 데이터를 읽어오기 위한 모듈
import os
# 웹 크롤링 차단하는 봇 우회 코드
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36')]
urllib.request.install_opener(opener)
u="https://comic.naver.com/webtoon/detail.nhn?titleId=703846&no=111&weekday=tue" # 웹툰 페이지
html = urllib.request.urlopen(u) # 웹 페이지 요청
result = BeautifulSoup(html.read(), "html.parser") # html의 관점에서 문자열을 이해해달라고 하는 의미(html.parser)
name=result.findAll("h2")
title=name[1].text[0:4] # '여신강림'만 갖고와서 변수에 저장
print(title)
os.chdir("/Users/user/Desktop/")
os.mkdir(title) # /Users/user/DeskTop/에 '여신강림'이름의 파일 생성
일단 먼저 웹툰 사이트로 접속한 후 크롬 기준 도구 더보기에 개발자 도구에 들어가서 코드에 태그들을 분석해본다.
내가 현재 갖고 오고 싶은 정보는 웹툰 제목인 '여신강림'이므로 이 제목이 있는 부분의 해당 코드들을 살펴보자

보면 <h2>태그에 둘러싸여 있는 것을 알 수 있다. 하지만 h2에 따른 속성이 없으므로 일단 다음 코드를 통해 <h2>태그에 둘러싸인 것들을 전부 찾아 name이라는 변수에 저장한다. 그리고 출력해보면 다음과 같이 뜬다.
name=result.findAll("h2")

보면 2개 밖에 없는 것을 알 수 있고 이 중에서 name[1]에 내가 원하는 여신강림이라는 정보가 있다는 걸 알 수 있다.
name[1]에서 '여신강림'만 가져오려면 어떻게 해야 할까? 일단 name[1].text를 이용하여 text만 가져와보자
그럼 다음과 같다.

이제 인덱스를 활용하여 인덱스 0부터 3까지만 가져오면 된다. -> name[1].text[0:4]
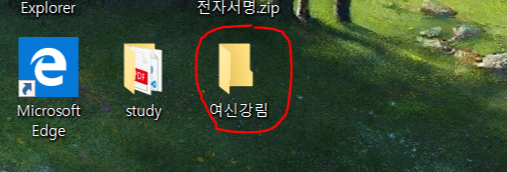
이제 1단계의 코드를 실행해보면 다음과 같이 이름이 '여신강림'인 파일이 하나 생성되는 걸 볼 수 있다.
(경로는 /Users/user/Desktop/에 생성되게 해놓았다.)

2단계. 웹툰 '여신강림' 메인 페이지에서 각 화의 링크들만 가져오기(10개)
big = "https://comic.naver.com/webtoon/list.nhn?titleId=703846&weekday=tue" #웹툰 최신 10개의 회차가 있는 페이지
html = urllib.request.urlopen(big)
result = BeautifulSoup(html.read(), "html.parser")
array=[]
list=result.findAll("td", {"class", "title"})
for s in list:
print(s.find("a")['href'])
array.append(s.find("a")['href']) # 전체 리스트 화면에서 각 화의 링크를 리스트에 담기
각 화의 이미지들을 가져오기 위해서는 각 회의 링크들을 먼저 가져온 후 각각의 웹페이지를 요청해야 하다.
웹툰의 메인 페이지에는 최신 10개화의 웹툰들이 있으므로 해당 웹 페이지 코드에서 링크들을 어떻게 가져올 수 있는지 분석해보자
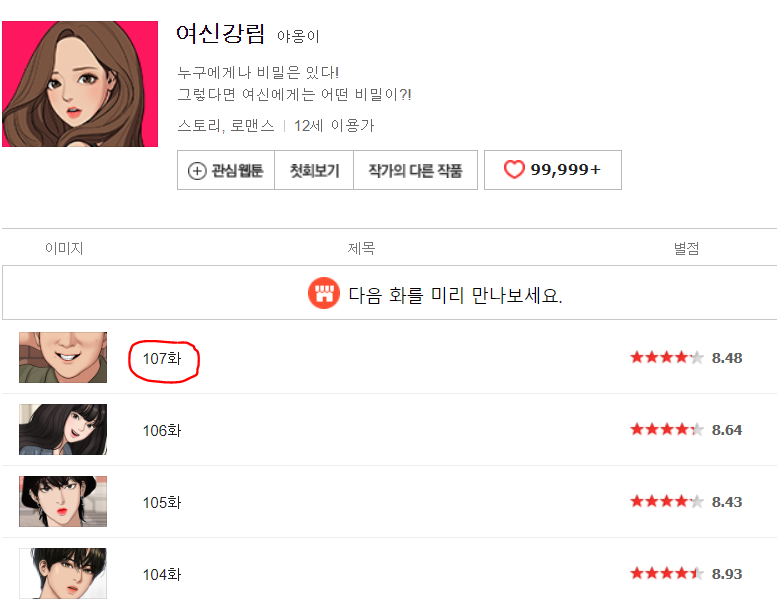

위의 코드는 동그라미 친 부분 즉 107화로 들어가는 링크가 있는 부분이다. 보면 td태그 안에 a태그 안에 링크가 있는 것을 알 수 있다. 일단 td태그 안에 있는 a태그의 href요소 부분 링크만 가져와보자 결과는 다음과 같다.
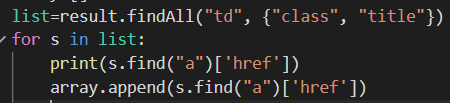

다음과 같이 우리가 필요로 하는 링크들만 가져올 수 있다.(최근에 수정해서 새로운 화가 업데이트되어 104~113화까지 출력되었다.)
3단계. 가져온 각 회차의 링크의 웹 페이지를 요청하여 각 화 이름을 가져와 그 이름의 파일을 '여신강림'파일 안에 만들고 새로 만들어진(예를 들어 107화) 파일 안에 각 회차의 모든 이미지들을 저장한다.
for i in range(len(array)):# 각 회차별로 동작하게끔(10개의 회차가 있으므로 10번 동작)
url="https://comic.naver.com"+array[i]
html2 = urllib.request.urlopen(url) # 해당 회차 웹 페이지 요청
result2 = BeautifulSoup(html2.read(), "html.parser")
search=result2.findAll("img", {"alt" : "comic content"}) # 해당 웹 페이지에서 저장할 웹툰 이미지 링크를 찾기 위함
name=result2.findAll("meta", {"property" : "og:description"}) # 해당 차 제목의 파일을 만들기 위해 제목을 가져옴 ex) 107화
for s in name:
print(s['content'])
little=s['content']
os.chdir("/Users/user/Desktop/"+title)
os.mkdir(s['content']) # /Users/user/Desktop/여신강림/ 에 해당 회차 제목의 파일을 생성
i=1 # 다음 회차로 넘어간 후 다시 이미지 파일 이름을 1.jpg으로 시작하기 위한 초기화
for s in search:
picture = s['src'] # 해당 회차의 모든 웹툰 이미지 링크를 담는 변수
outpath='C:/Users/user/Desktop/'+title+'/'+little+'/'
outfile=str(i)+'.jpg'
urllib.request.urlretrieve(picture, outpath+outfile)
# 웹툰 이미지를 /Users/user/Desktop/여신강림/'해당회차 제목'/에 저장한다. 이미지 이름은 1.jpg에서 시작하여 1씩 증가
i += 1
각 화의 이름을 파일 제목으로 만들어야 하므로 먼저 각 화의 이름을 가져와야 한다.
위의 코드에서 각 화의 링크는 다음과 같이 표현했다.
url="https://comic.naver.com"+array[i]
이 링크의 웹 페이지의 코드에서 각 화의 이름이 어디에 있는지 살펴보자

property="og:description"인 meta태그 안에 content값이 107화 즉, 우리가 만들어야 하는 파일 제목이므로 findAll함수를 통해 가져온다. 그리고 /Users/user/Desktop/여신강림 파일 아래에 107화가 이름인 파일을 만들자.
메인 페이지에 총 10개의 회차가 있으므로 10개의 파일을 만들게 된다. 결과는 다음과 같다.


이제 마지막으로 각 파일에 각 화의 웹툰 이미지를 저장만 하면 끝이다.
각 화의 코드를 자세히 보니 모든 이미지는 아래와 같이 속성 alt값이 comic content인 img태그 안에 있다는 것을 알 수 있었다.

따라서 위에서 만든 /Users/user/Desktop/'각 화의 이름' 파일 안에 이미지들을 urllib.request.urlretrieve()함수를 통해 저장하자. 나는 이미지 파일 이름을 각 화마다 1.jpg에서 시작해서 1씩 증가하며 2.jpg 3.jpg이런 식으로 저장하기 위해 변수 i를 사용하여 처음에 1로 초기화 시켜놓은 다음 이미지를 하나씩 저장할 때 마다 1씩 증가하게 하여 저장하였고 다음 화로 넘어가는 시점에서 다시 1로 초기화 시켜 모든 파일의 첫번째 이미지 이름은 1.jpg가 되도록 하였다.
최종적으로 결과 화면을 보면 바탕화면 아래 여신강림 파일이 생성되었고 그 안에 각 화의 제목을 이름으로 한 파일들이 총 10개가 생성되었고 그 안에 웹툰 이미지들이 저장되어 있는 것을 확인할 수 있다.



'Python > SWING study' 카테고리의 다른 글
| 게임 메크로 python (1to50 ) (0) | 2020.06.02 |
|---|---|
| 웹 클롤링(python) (0) | 2020.05.21 |
| UP & DOWN GAME 2 (Python) (0) | 2020.04.15 |
| Up&Down Game (python) (0) | 2020.04.07 |
| Python 문자열 함수와 리스트 함수 (1) | 2020.04.07 |
