
minhui study
Tensorflow 2.0 - dataset (MNIST) 본문
Data Preprocess (MNIST)
TensorFlow에서 제공해주는 데이터셋(MNIST) 예제 불러오기


* train_x와 train_y는 모델 학습에 사용되는 훈련 세트이다.
* test_x와 test_y는 모델 테스트에 사용되는 테스트 세트이다.
* 이미지는 28x28 크기의 Numpy배열이고 픽셀 값은 0과 255사이이다. label은 0에서 9까지의 정수 배열이다.
( 훈련 세트에는 60000개의 레이블이 있고 각 레이블은 0과 9 사이이 정수이다. )
Image Dataset 들여다보기
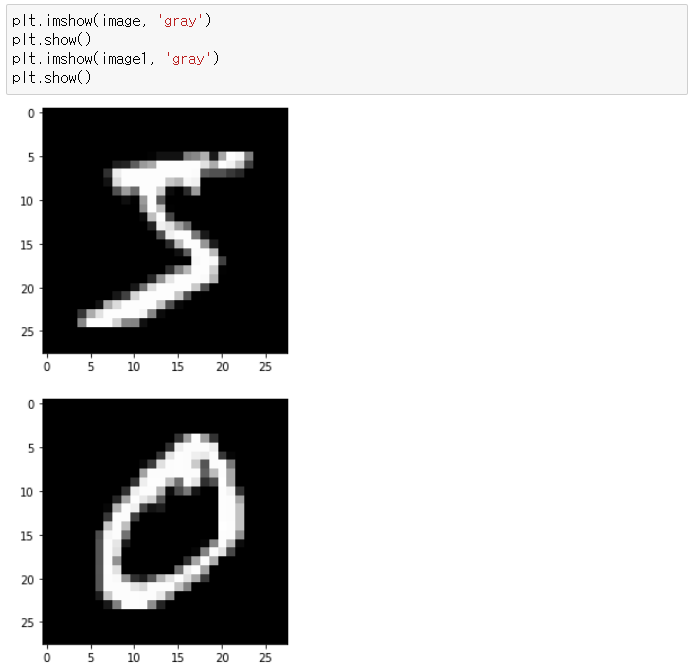
● Data 하나만 뽑기

● 시각화해서 확인
Channel 관련
[Batch Size, Height, Width, Channel]
GrayScale이면 1, RGB이면 3으로 만들어줘야 한다.
● 데이터 차원 수 늘리기(numpy)

● TensorFlow 패키지 불러와 데이터 차원수 늘리기 (tensorflow)

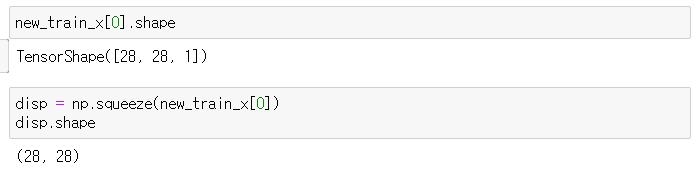
* np.squeeze()
→ np.squeexe(배열, 차원)은 배열에서 1차원인 축을 제거하는 것이다.
* newaxis

* array를 고차원으로 다음과 같이 만들낼 수도 있다.

reshape vs newaxis?
(4,1)을 (2,2)으로는 reshape이 가능하지만 (4,1)을 (3,3)으로는 바꿀 수 없다.
● 시각화

Label Dataset 들여다보기
Label 하나를 열어서 Image와 비교하여 제대로 들어갔는지. 어떤 식으로 저장 되어있는지 확인한다.


OneHot Encoding
컴퓨터가 이해할 수 있는 형태로 변환해서 Label을 주도록 한다.


● label 확인 후 to_categorical 사용 ( label = train_y[2] #4 )

● onehot encoding으로 바꾼 것과 이미지 확인

'딥러닝,인공지능' 카테고리의 다른 글
| Tensorflow 2.0 - Optimizer 및 Training / Evaluating & Predicting (0) | 2021.01.12 |
|---|---|
| Tensorflow 2.0 - 각 Layer별 역할 개념 및 파라미터 파악 (0) | 2021.01.08 |
| Tensorflow 2.0 - Tensorflow 기초 사용법 (0) | 2021.01.08 |
| Image Visualization ( 이미지 시각화 기초) (0) | 2021.01.07 |
| Graph Visualizaion ( 시각화 기초 ) (0) | 2021.01.06 |



