
minhui study
Tensorflow 2.0 - Optimizer 및 Training / Evaluating & Predicting 본문
전체적인 학습 과정

Optimizer 및 Training

Build Model


Preprocess ( 데이터 전처리 )
- tf.data 사용 ( 텐서텐서플로우 공식홈페이지에서 말한 expert한 방법 )
- MNIST Dataset 준비
- RGB로 channel이 이미 3이었다면 차원을 늘려줄 필요가 없지만 gray scale이기 때문에 늘려줘야 한다.



▶ Generate batch data with tf.data
- from_tensor_slices(): 일반 이미지나 array를 넣을 때 list형식으로 넣어준다. 이미지 경로들이 담긴 리스트 일 수도 있고, raw 데이터의 리스트 일 수도 있다.
- shuffle() : 한번 epoch이 돌고 나서 랜덤하게 섞을 것인지 정한다.
- batch(batch_size) : 배치 사이즈(한번에 가져오는 데이터 사이즈)를 정한다.
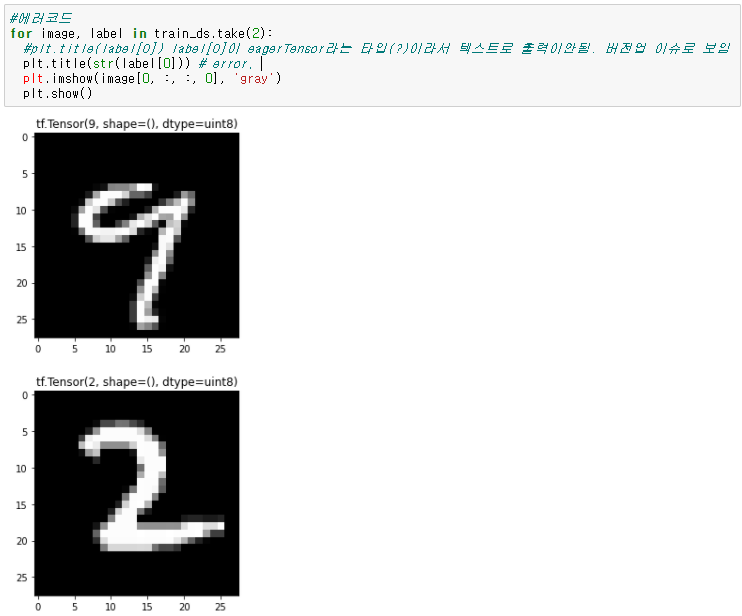
▶ Visualize Data
matplotlib를 불러와서 데이터 시각화하기

Optimization (신경망 학습 최적화 )
▶ Loss Function(손실 함수)
손실 함수는 실제값과 예측값의 차이를 수치화해주는 함수이다.
오차가 클수록 손실 함수의 값이 크고, 오차(loss와 cost)가 작을수록 손실 함수의 값이 작아진다.
→ Categorical(다중분류) vs Binary(이진분류)

→ sparse_categorical_crossentropy vs categorical_crossentropy
: Sparse_categorical_croosentorpy는 각 샘플이 오직 하나의 class에 속할 때 사용하고,
Categorical_crossentropy는 각 샘플이 여러 개의 class에 속할 수 있거나 label이 soft probalities일 때 사용하는 것이 좋다.
ex) [0.5, 0.3, 0.2]
* Loss 계산 결과는 매우 유사하다. 실제 계산 수식에 차이가 없기 때문에 정확도에 영향을 끼치지 않는다.

▶ Metrics
모델을 평가하는 방법, 평가지표로 학습을 통해 목표를 얼마나 잘못 또는 잘 달성했는지를 나타내는 값이다.
* accuracy : 전체에서 얼마나 맞혔는지


▶ Optimizer 적용
Loss Function을 줄여나가면서 학습하는 방법은 어떤 optimizer를 사용하느냐에 따라 달라진다.
- tf.keras.optimizers.SGD()
- tf.keras.optimizers.RMSprop()
- tf.keras.optimizers.Adam()

* loss값을 평균값을 내어 사용하면 값들이 더 깔끔하다.
Training
본격적으로 학습 들어가기
▶ @tf.function - 기존 session 열었던 것처럼 바로 작동 안 하고, 그래프만 만들고 학습이 시작되면 돌아가도록 한다.

Evaluating & Predicting

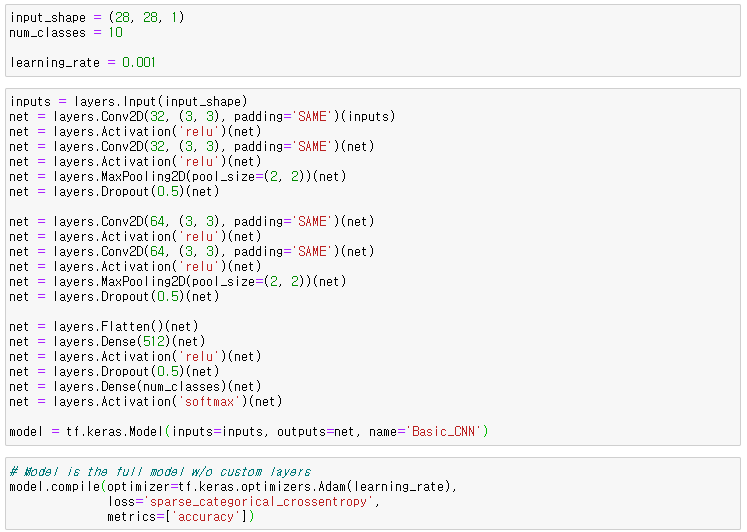
Build Model
Preprocess
데이터셋 불러오기

Training

Evaluating
▶ 학습할 모델 확인
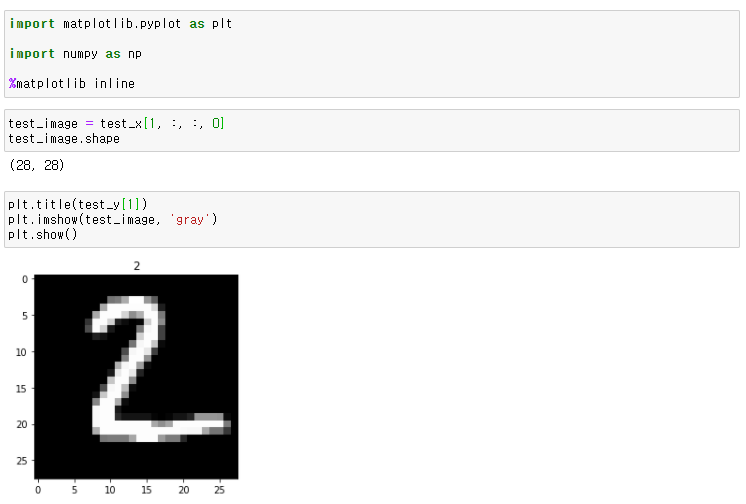
→ 모델에 input Data으로 확인 할 이미지 데이터 넣기

Test Batch
→ Batch로 Test Dataset 넣기

'딥러닝,인공지능' 카테고리의 다른 글
| Pytorch - Optimizer 및 Training / Evaluating & Predicting (0) | 2021.01.12 |
|---|---|
| Pytorch - 각 Layer별 역할 개념 및 파라미터 파악 (1) | 2021.01.12 |
| Tensorflow 2.0 - 각 Layer별 역할 개념 및 파라미터 파악 (0) | 2021.01.08 |
| Tensorflow 2.0 - dataset (MNIST) (0) | 2021.01.08 |
| Tensorflow 2.0 - Tensorflow 기초 사용법 (0) | 2021.01.08 |



