
minhui study
Pytorch - Optimizer 및 Training / Evaluating & Predicting 본문
PyTorch : Optimization & Training


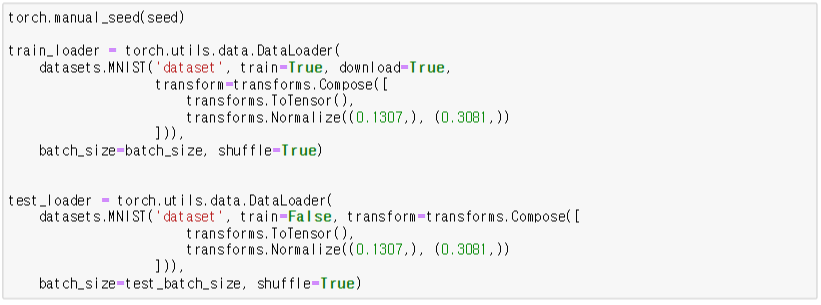
* 랜덤 생성에 사용되는 시드(seed)는 torch.manual_seed() 명령으로 설정
* batch size : 한 번의 batch(데이터셋)마다 주는 데이터 샘플의 size
* iteration : epoch를 나누어서 실행하는 횟수
Preprocess
파이토치에서는 데이터를 좀 더 쉽게 다룰 수 있도록 유용한 도구로서 데이터셋(Dataset)과 데이터로더(DataLoader)를 제공한다. 이를 사용하면 미니 배치 학습, 데이터 셔플(shuffle), 병렬 처리까지 간단히 수행할 수 있다. 기본적인 사용 방법은 Dataset을 정의하고, 이를 DataLoader에 전달하는 것이다.
Model

- nn.Module은 신경망 모듈로 매개변수를 캡슐화하는 간편한 방법이다.
- Convolution이란 이미지 위에서 stride값만큼 filter를 이동시키면서 겹쳐지는 부분의 각 원소 값을 곱해서 모두 더한 값을 출력하는 연산이다.
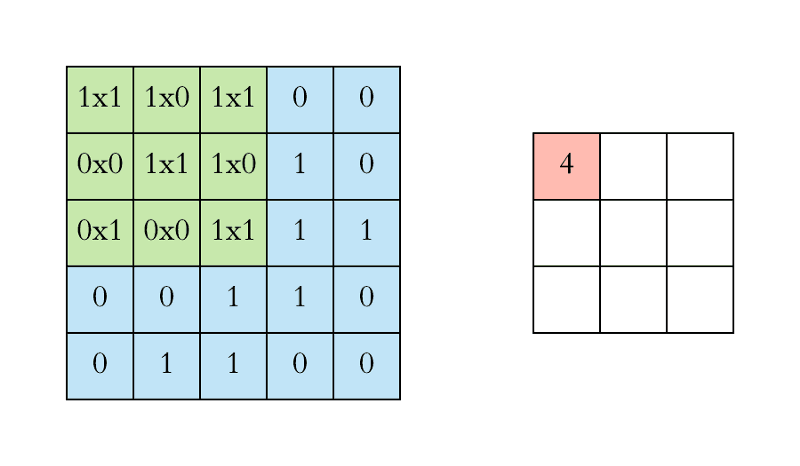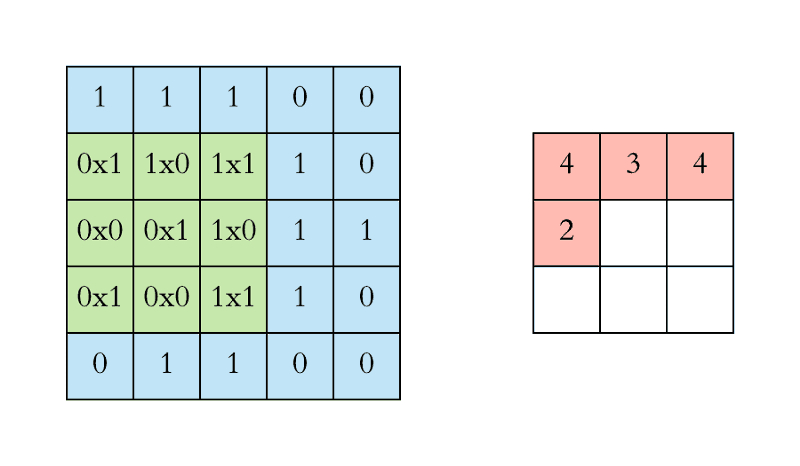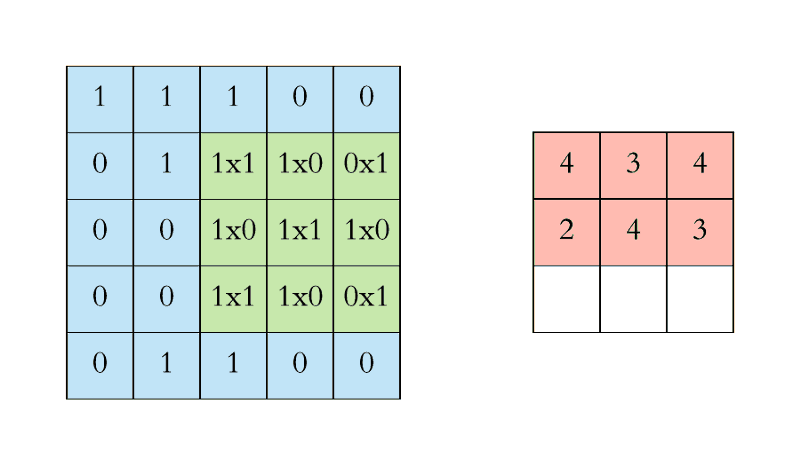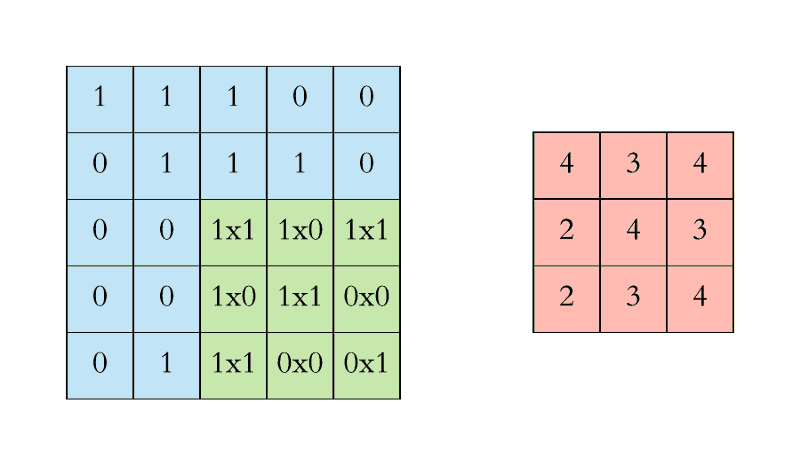
- nn.Conv2D는 in_channels, out_channels, kernel_size 이외에는 디폴트값이 설정되어 있다.
- in_channels: 받게 될 channel의 갯수
- out_channels: 보내고 싶은 channel의 갯수
- kernel_size: 만들고 싶은 kernel(weights)의 사이즈
- Linear Module은 선형 함수를 사용하려 입려으로부터 출력을 계산하고 내부 Tensor에 가중치와 편향을 저장한다.
- forward()는 모델이 학습데이터를 입력받아서 forward propagation을 진행시키는 함수이고, 반드시 forward라는 이름의 함수여야 한다.
* forward함수만 정의하고 나면 (변화도를 계산하는)backward함수는 autograd를 사용하여 자동으로 정의된다.
Optimization
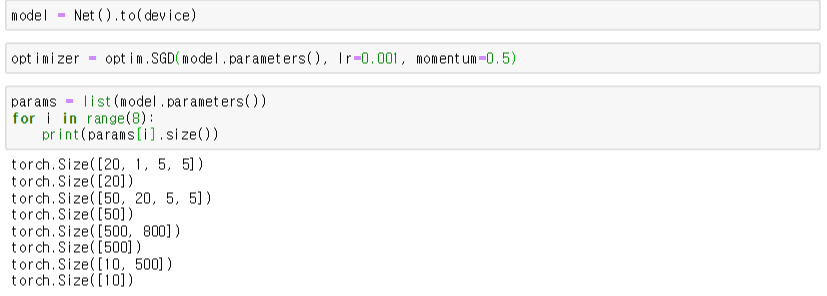
- Model과 Optimization 설정
- Optimizer를 정의하는데 이때 SGD 생성자에 model.parameters()를 이용하여 W와 b를 전달한다.
Before Training
- 학습하기 전에 Model이 Train할 수 있도록 Train Mode로 변환
- Convolution 또는 Linear 뿐만 아니라, DropOut과 추후에 배우게 될 Batch Normalization과 같이 parameter를 가진 Layer들도 학습하기 위해 준비

- 모델에 넣기 위한 첫 Batch 데이터 추출

- 추출한 Batch 데이터를 cpu 또는 gpu와 같은 device에 compile

- gradients(기울기)를 clear해서 새로운 최적화 값을 찾기 위해 준비하고 준비한 데이터를 model에 input으로 넣어 output을 얻는다.

- Model에서 예측한 결과를 Loss Function에 넣는다. 여기서는 Negative Log-Likelihood Loss라는 Loss Function을 사용한다.
- Back Propagation을 통해 Gradients를 계산한다.
* Back Propagation이란? 뽑고자 하는 target값과 실제 모델이 계산한 output이 얼마나 차이가 나는지 구한 후 그 오차값을 다시 뒤로 전파해가면서 각 노드가 가지고 있는 변수들을 갱신하는 알고리즘이다. - 계산된 Gradients는 계산된 걸로 끝이 아니라 Parameter에 Update

Start Training
→ 위의 최적화 과정을 반복하여 학습 시작


Evaluating & Predicting
- 앞에서 model train()모드로 변한 것처럼 평가할 때는 model.eval()로 설정
- Batch Normalization이나 Drop Out 같은 Layer들을 잠금

- autograd engine, 즉 backpropagation이나 gradient 계산 등을 꺼서 memory usage를 줄이고 속도를 높인다.


'딥러닝,인공지능' 카테고리의 다른 글
| [이미지 분석으로배우는 tensorflow2.0 와 Pytorch] - tensorflow2.0 fit_generator (0) | 2021.01.24 |
|---|---|
| [이미지 분석으로배우는 tensorflow2.0 와 Pytorch] - Preprocess (0) | 2021.01.20 |
| Pytorch - 각 Layer별 역할 개념 및 파라미터 파악 (1) | 2021.01.12 |
| Tensorflow 2.0 - Optimizer 및 Training / Evaluating & Predicting (0) | 2021.01.12 |
| Tensorflow 2.0 - 각 Layer별 역할 개념 및 파라미터 파악 (0) | 2021.01.08 |



